

Nie po raz pierwszy piszemy o lokalnym uruchamianiu dużych modeli językowych. Lokalnie, czyli na naszym urządzeniu, a nie w chmurze. Nasze dane pozostają bezpieczne, nie jesteśmy uzależnieni od dostępu do internetu i nie musimy płacić abonamentów za co ciekawsze możliwości. Niby można korzystać z darmowych wersji chmurowych AI, ale ich możliwości są ograniczone i nie raz otrzymywałem komunikat, że w powodu przeciążenia AI, mam spróbować ponownie poza godzinami szczytu (niezależnie od pory dnia i nocy).
Nie liczyłbym na to, że modele uruchamiane lokalnie zastąpią całkowicie te w chmurze. Co bardziej zaawansowane modele potrzebują naprawdę potężnego zaplecza sprzętowego i przy skomplikowanych czy specjalizowanych zadaniach to właśnie one będą sprawdzać się najlepiej. Jednak w przypadku codziennych zadań i mniej skomplikowanych czynności, nie ma potrzeby polegania na serwerach na drugim końcu świata. Tu w zupełności wystarczy niewielki lokalny model do szybkiego przetwarzania offline - na przykład Gemma 4. Dla przykładu Gemma 4 E2B to ultralekki model edge AI od Google zoptymalizowany na urządzenia mobilne i IoT z niskim zużyciem pamięci i baterii.
O co to całe halo z Gemma 4?
Jak powszechnie wiadomo, z nowymi modelami Google kwestie są dwie: mniejszy rozmiar modeli (więc można je używać na mniej wydajnych urządzeniach z mniejszą ilością RAM, nawet jak smartfony) oraz przejście na licencję Apache 2.0 (czyli jak w Mistral, czy Qwen). Wbrew pozorom, druga kwestia jest równie istotna, bo modeli Gemma 4 możesz używać w produktach komercyjnych, wdrażać i dystrybuować bez żadnych opłat. No i modyfikować.
Google zastosował w Gemma 4 kilka ciekawych technik optymalizacyjnych - modele nie przetwarzają już kontekstu w każdej warstwie (podział na warstwy lokalne i globalne), nie obliczają już KV Cache za każdym razem od nowa i posiadają natywne wywołanie funkcji do wywoływania narzędzi. Testy pokazują, że to działa i to działa doskonale przy zużyciu znacznie mniejszych zasobów sprzętowych.
Na ten moment w rodzinie Gemma 4 znajdują się cztery modele: E2B, E4B, 31B i 26B A4B. Dwa pierwsze uruchomisz nawet na telefonie, 26B A4B na laptopie (8GB VRAM powinno styknąć), a 31B… no, tu już potrzeba konkretnego akceleratora. Wszystkie modele są multimodalne, czyli przetwarzają wiele typów danych wejściowych, a mniejsze modele również audio.
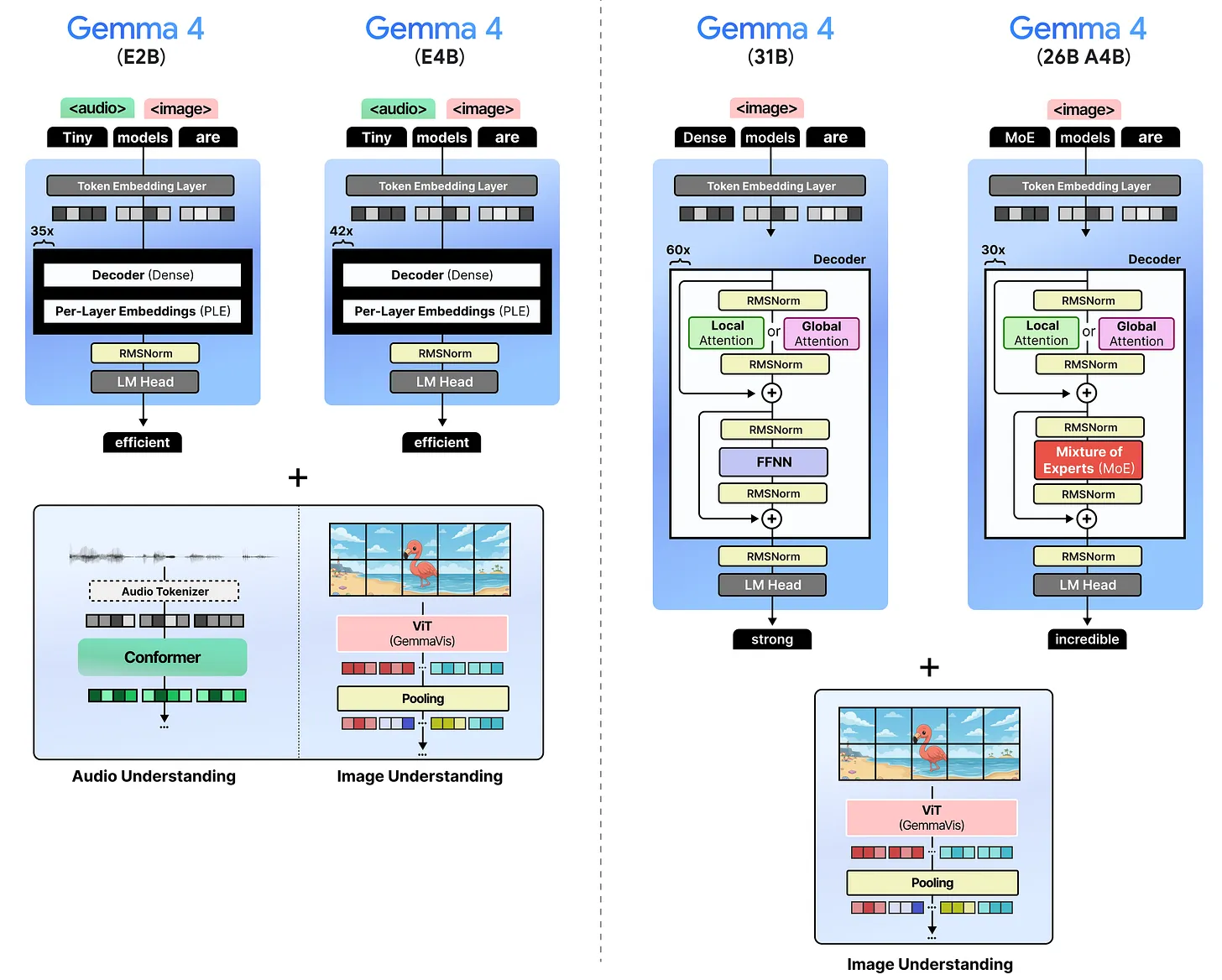
Źródło: maartengrootendorst.com
Do czego przydadzą się lekkie modele offline jak E2B, a do czego nie?
Nie ma co się łudzić, że niewielki model na smartfonie przyda nam się do wszystkiego. Ale do czego może się przydać?
-
edycja tekstu, pisanie e-maili, wyjaśnienia koncepcji
-
rozwiązywanie problemów krok po kroku, czy rozkładanie tematów na czynniki pierwsze
-
proste kodowanie, czy debugowanie skryptów
-
rozpoznawania obrazów, czy transkrypcja audio offline
-
wywoływanie narzędzi, analiza sensorów, czy myślenie krokowe
Do czego małe modele nam się NIE przydadzą?
-
bądźmy realistami, zadania wymagające dużych zasobów, czy głębokiej inteligencji będą poza ich zasięgiem
-
tak samo odpadają złożone analizy logiczne, czy długie łańcuchy myślowe
-
odpadają zadania z dłuższym kontekstem
-
nie liczmy na profesjonalne kodowanie (zakładając, że większe modele robią to profesjonalnie...)
-
ani na przetwarzanie wideo i audio w złożonych scenariuszach
Jak zainstalować nowe modele Gemma 4 lokalnie na smartfonie?
Nic prostszego, nie trzeba żadnych kombinacji. Wystarczy w sklepie Google Play znaleźć aplikację Google AI Edge Gallery.
Następnie wybieramy model, pobieramy go i uruchamiamy - wszystko za pomocą kilku kliknięć - na moim biednym telefonie inicjacja modelu w AI Chat trwała około minuty. Załadowany model można konfigurować pod kątem tokenów, temperatury, czy urządzenia do obliczeń. I tak - Gemma 4 działa również po polsku.
Sam uruchomiłem Gemma 4 E2B na budżetowym smartfonie Samsung Galaxy A25 5G (6 GB) i przy zwykłej konwersacji model działał szybko i zaskakująco sprawnie. Wedle informacji aplikacji, do obliczeń wykorzystywane było GPU (procesor Exynos 1280). Dajcie znać w komentarzach, czy w waszych smartfonach udało się włączyć do akcji NPU.
Ale, ale - AI Chat to tylko jedna z opcji w tej aplikacji. Jest tu Ask Image do identyfikacji obiektów lub odczytywania tekstu ze zdjęć, Audio Scribe do szybkich transkrypcji głosu offline, Agent Skills do automatyzacji codziennych zadań bez internetu, a nawet Prompt Lab do testów modelu lokalnie. Znalazło się tu miejsce nawet na eksperymentalną mini grę Tiny Garden, która jest sterowana głosem i to naturalnym językiem.
Rewolucja? A jakże!
W skrócie - nowe modele to więcej kontekstu, mniej zużytego RAM-u i szybsza inferencja. To rozwiązanie idealne dla agentów AI, działających offline na urządzeniach, gdzie liczy się każdy gigabajt.
Nowe wersje mają możliwości znacznie większych modeli, które do tej pory wymagały potężnych wielkości pamięci RAM i tym samym pozostawały niedostępne dla zwykłych użytkowników, dysponującym sprzętem o ograniczonych możliwościach.
Warto wspomnieć, że miniaturyzację przeszedł również nasza rodzima AI Bielik, który dzięki wsparciu NVIDII ewoluowała do wersji Minitron, ale o tym... opowiem wam już następnym razem.
Spodobało Ci się? Podziel się ze znajomymi!

Pokaż / Dodaj komentarze do:
LLM lokalnie na twoim telefonie. Jak uruchomić nowe modele Gemma 4?