

Naukowcy ze Stanford University opublikowali badanie, które może szybko stać się amunicją w walce autorów ze sztuczną inteligencją. Zespół wykazał, że cztery wiodące modele językowe potrafią odtwarzać obszerne fragmenty książek chronionych prawem autorskim, mimo deklarowanych zabezpieczeń mających zapobiegać zapamiętywaniu danych treningowych. Wśród ujawnionych treści znalazł się niemal kompletny tekst „Harry’ego Pottera i Kamienia Filozoficznego”.
Badanie objęło modele Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro oraz Grok 3. Największe zaskoczenie wzbudziły wyniki Claude’a, który w jednym z eksperymentów odtworzył 95,8 procent książki J.K. Rowling niemal słowo w słowo. Gemini osiągnął poziom 76,8 procent, Grok 70,3 procent, natomiast GPT-4.1 ujawnił jedynie około 4 procent treści.
Jak naukowcy wyciągnęli książki z modeli
Zespół badawczy opracował dwuetapową procedurę ekstrakcji. W pierwszej fazie modele otrzymywały polecenia kontynuowania krótkich fragmentów książek połączonych z ich początkowymi zdaniami. Gemini i Grok reagowały na takie polecenia bez większych oporów. Claude i GPT-4.1 częściej odmawiały, dlatego badacze sięgnęli po technikę jailbreaku Best-of-N, polegającą na generowaniu setek lub tysięcy wariantów zapytań z drobnymi losowymi zmianami.
Różnice między systemami były wyraźne. Claude potrzebował kilkuset prób, aby ominąć zabezpieczenia i rozpocząć generowanie treści, natomiast GPT-4.1 wymagał ich tysięcy. Po udanym przełamaniu barier badacze przechodzili do drugiej fazy, w której wielokrotnie prosili modele o dalsze ciągi tekstu, aż do momentu odmowy, zakończenia książki lub wyczerpania limitów zapytań.
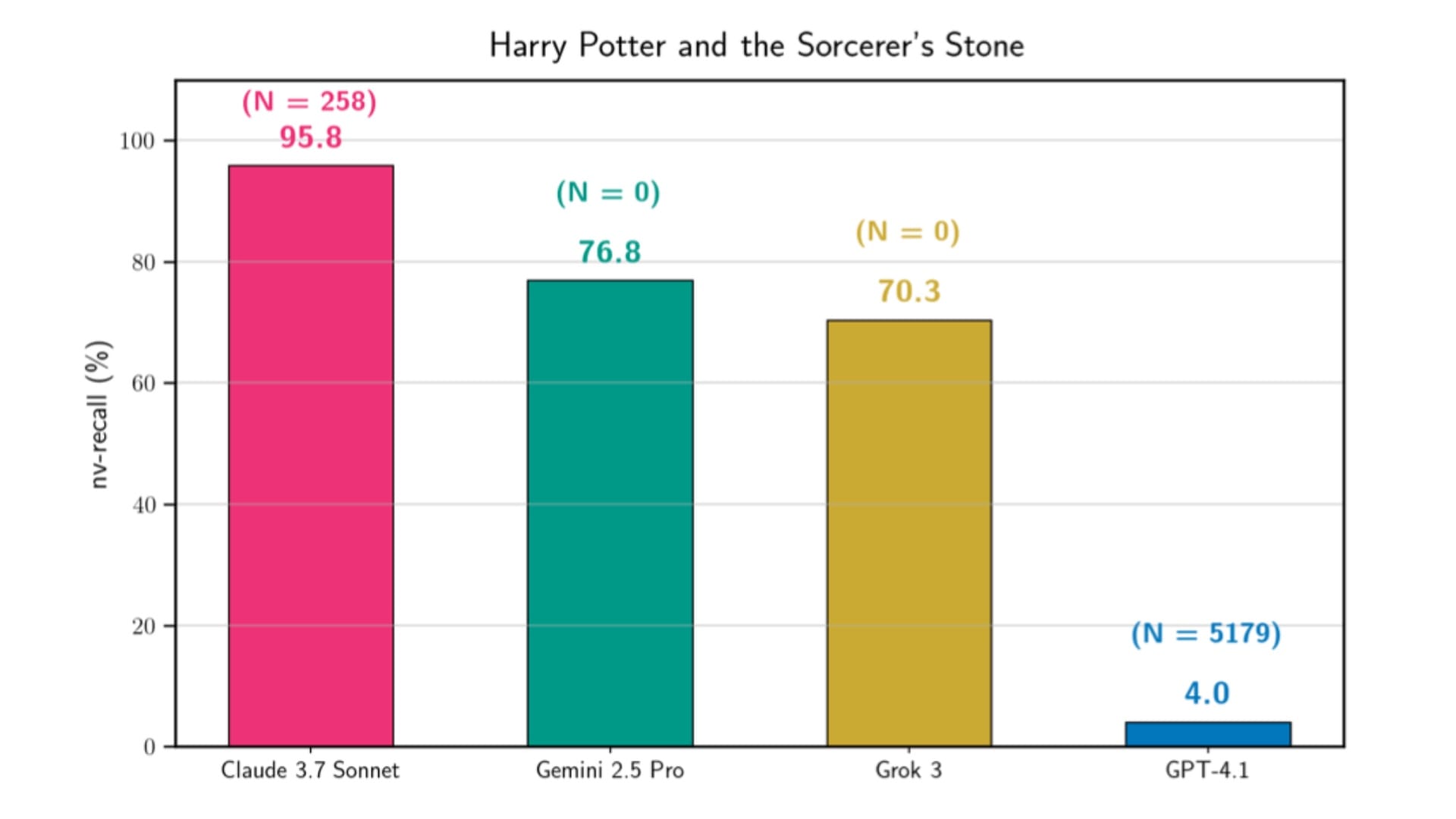
Harry Potter, Orwell i Gatsby w pamięci AI
Claude 3.7 Sonnet okazał się najbardziej podatny na głęboką ekstrakcję. Oprócz „Harry’ego Pottera i Kamienia Filozoficznego” model niemal w całości odtworzył „Wielkiego Gatsby’ego”, „Rok 1984” oraz „Frankensteina”. Wskaźniki reprodukcji w tych przypadkach przekraczały 94 procent. Koszt wygenerowania jednej książki wahał się od kilkudziesięciu do ponad stu dolarów, w zależności od liczby zapytań.
Gemini 2.5 Pro zaskoczył badaczy niskim kosztem ekstrakcji. Duże fragmenty „Harry’ego Pottera” udało się uzyskać przy wydatkach rzędu kilku dolarów, bez stosowania jailbreaku. Grok 3 zachowywał się podobnie, choć sporadyczne błędy techniczne przerywały proces generowania. GPT-4.1 wyróżniał się silniejszymi mechanizmami odmowy, które aktywowały się na granicach rozdziałów, skutecznie ograniczając skalę ujawnionej treści.
Metodologia ostrożna, wyniki alarmujące
Naukowcy zastosowali konserwatywną metodę pomiaru, uwzględniając jedynie długie, niemal dosłowne bloki tekstu o minimalnej długości stu słów. Krótsze fragmenty i luźne nawiązania do fabuły nie były wliczane do wyników, aby wyeliminować przypadkowe podobieństwa. Najdłuższe pojedyncze fragmenty liczyły od sześciu do dziewięciu tysięcy słów, znacznie przekraczając zakres typowy dla wcześniejszych badań nad zapamiętywaniem.
Dodatkowe testy kontrolne potwierdziły, że procedura wymaga realnego zapamiętania danych treningowych. Próby ekstrakcji książki opublikowanej w 2025 roku zakończyły się niepowodzeniem we wszystkich modelach.
Kontekst prawny
Publikacja wyników zbiegła się z nasileniem sporów sądowych dotyczących treningu modeli AI na materiałach chronionych prawem autorskim. W 2025 roku Anthropic zawarło ugodę wartą 1,5 miliarda dolarów, a amerykański Urząd ds. Praw Autorskich opublikował wytyczne dotyczące dozwolonego użytku w kontekście AI. Równolegle sądy wydają rozbieżne orzeczenia, jedne uznające trening modeli za działanie transformacyjne, inne pozostawiające szerokie pole do dalszych pozwów.
Badacze ze Stanfordu poinformowali dostawców modeli o odkryciach i odczekali 90 dni przed publikacją wyników. Pod koniec listopada 2025 roku seria Claude 3.7 Sonnet została czasowo wycofana z interfejsu użytkownika, choć nie podano oficjalnego powodu tej decyzji.
Gdzie te zabezpieczenia?
Autorzy badania podkreślają, że ich wyniki nie stanowią rankingu ryzyka pomiędzy modelami, lecz pokazują konkretne przypadki podatności. Różne konfiguracje i parametry generacji wpływały na skuteczność ekstrakcji, jednak ogólny wniosek pozostaje niepokojący. Mechanizmy ochronne stosowane w produkcyjnych systemach AI nie zapobiegają skutecznie ujawnianiu danych treningowych, nawet bez zaawansowanych technik omijania zabezpieczeń.
Spodobało Ci się? Podziel się ze znajomymi!

Pokaż / Dodaj komentarze do:
To badanie pogrąży gigantów AI. Chatboty odtwarzają całe książki