

Sztuczna inteligencja odgrywa coraz większą rolę w dostarczaniu informacji, jednak jej dokładność pozostawia wiele do życzenia. Modele AI, choć imponujące pod względem zdolności przetwarzania danych, często cierpią na problem tzw. halucynacji – generowania błędnych informacji, które są podawane z pełnym przekonaniem.
Podwajanie nieprawdziwych danych i brak precyzji w cytowaniu źródeł to problemy, z którymi programiści mierzą się na co dzień. Do tej pory trudno było jednak oszacować faktyczny poziom niedokładności tych systemów. Teraz badacze z Tow Center for Digital Journalism postanowili to zmierzyć.
Wyszukiwarki AI pod lupą
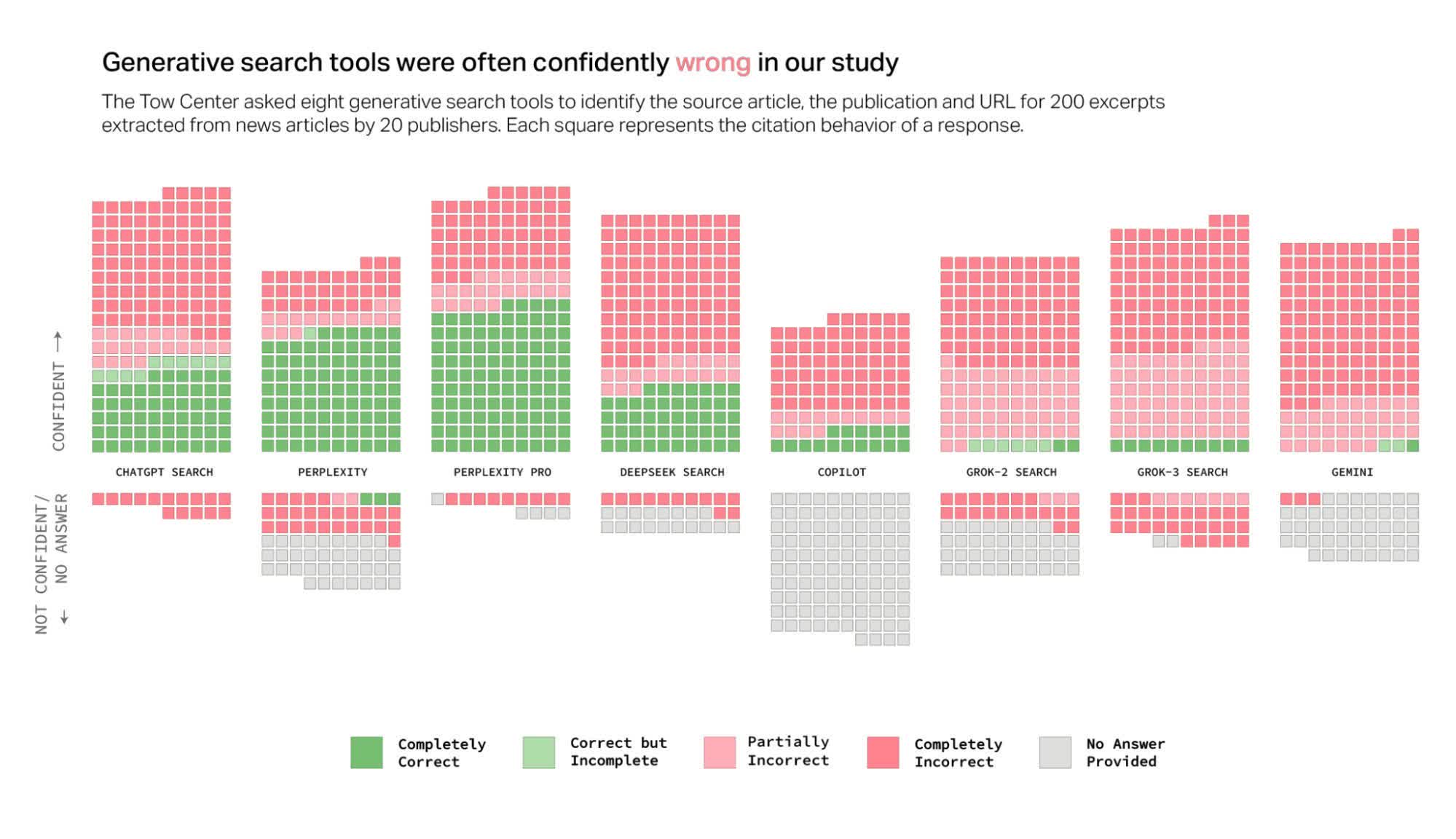
Zespół badaczy przeanalizował osiem wyszukiwarek opartych na AI, w tym ChatGPT Search, Perplexity, Perplexity Pro, Gemini, DeepSeek Search, Grok-2 Search, Grok-3 Search oraz Copilot. Głównym celem było sprawdzenie, jak dokładnie te narzędzia wyszukują i cytują źródła oraz jak często odmawiają odpowiedzi na zapytania użytkowników.
W ramach badania wybrano losowo 200 artykułów prasowych z 20 różnych wydawnictw (po 10 z każdego). Artykuły te zostały wcześniej zweryfikowane pod kątem ich obecności w pierwszej trójce wyników Google dla wybranego cytatu. Następnie przeprowadzono identyczne wyszukiwania w każdej z testowanych wyszukiwarek AI. Ocena dokładności opierała się na trzech kryteriach: czy narzędzie poprawnie wskazało źródłowy artykuł, organizację informacyjną oraz adres URL.
Rezultaty: AI zawodzi w 60% przypadków
Po przeanalizowaniu wyników badacze sklasyfikowali każdą odpowiedź na skali od „całkowicie poprawnej” do „całkowicie niepoprawnej”. Wnioski? Poza obiema wersjami Perplexity, pozostałe wyszukiwarki AI nie radziły sobie dobrze. Łącznie narzędzia AI były niedokładne w aż 60% przypadków. Co więcej, problem ten potęguje fakt, że modele AI prezentują błędne informacje z pełnym przekonaniem, wzmacniając tym samym swoją wiarygodność w oczach użytkowników.
Zjawisko to nie jest nowe, ale dopiero teraz udało się je precyzyjnie oszacować. LLM-y (duże modele językowe) często określa się mianem „najsprytniejszych kłamców wszech czasów” – prezentują informacje w sposób niezwykle przekonujący, nawet jeśli są one całkowicie błędne. Potrafią również „bronić” swoich fałszywych twierdzeń lub wymyślać nowe, gdy użytkownik próbuje je podważyć.
ChatGPT – najlepszy czy najgorszy?
ChatGPT Search jako jedyne narzędzie odpowiedziało na wszystkie 200 zapytań, co może sugerować jego wysoką użyteczność. Jednak tylko 28% odpowiedzi było całkowicie poprawnych, podczas gdy 57% było całkowicie niepoprawnych. To pokazuje, że chociaż ChatGPT zawsze udziela odpowiedzi, ich rzetelność pozostawia wiele do życzenia.
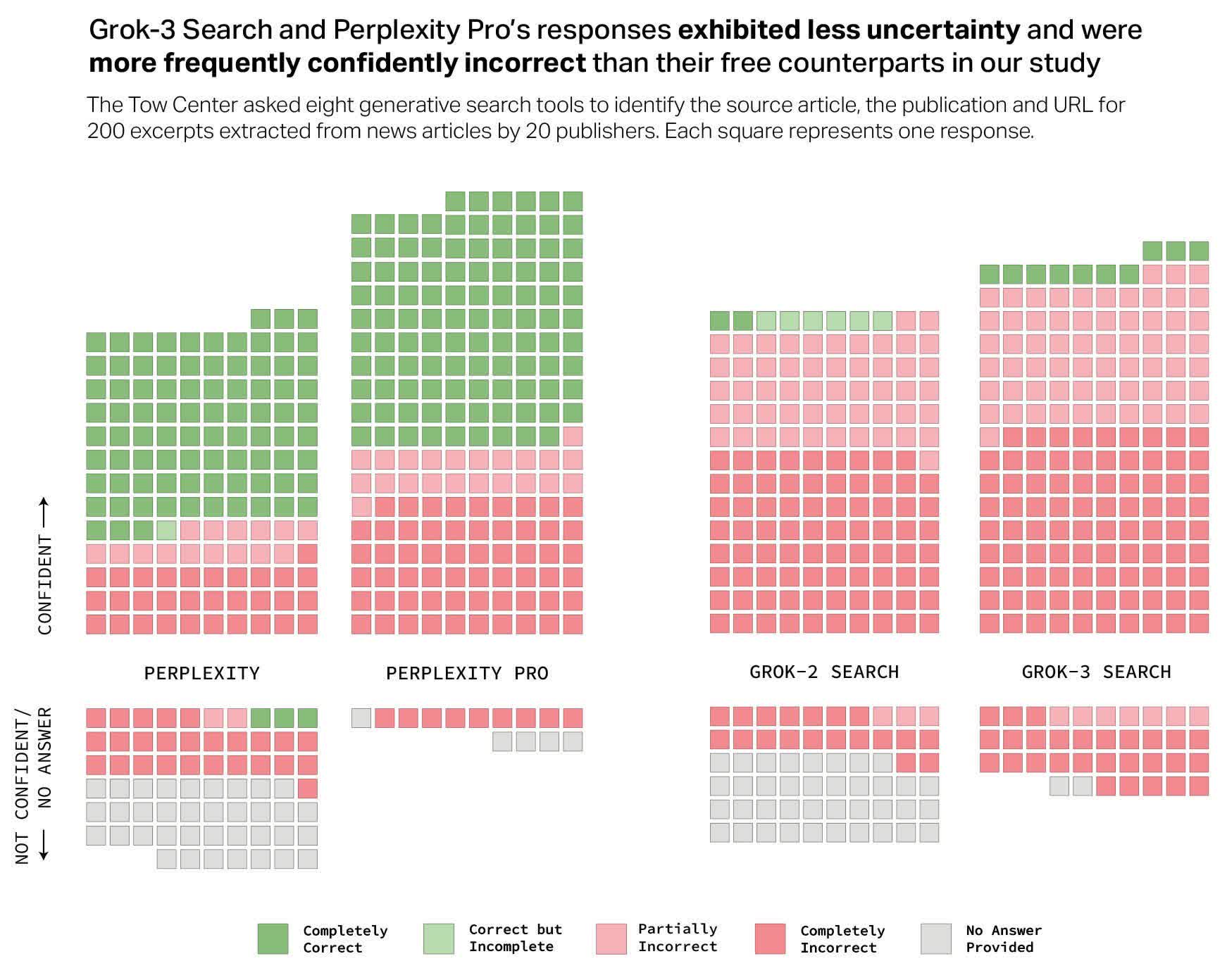
Nie jest to jednak najgorzej radząca sobie wyszukiwarka w badaniu. Szczególnie źle wypadły obie wersje Grok AI od X. Grok-3 Search uzyskał alarmująco niską skuteczność – aż 94% jego odpowiedzi było niedokładnych. Copilot Microsoftu również nie zachwycił – w 104 przypadkach na 200 całkowicie odmówił odpowiedzi. Spośród pozostałych 96 wyników jedynie 16 było „całkowicie poprawnych”, 14 „częściowo poprawnych”, a aż 66 „całkowicie niepoprawnych” – co oznacza około 70% niedokładności.
Czy użytkownicy są oszukiwani?
Jednym z najbardziej kontrowersyjnych aspektów jest fakt, że firmy technologiczne nie są transparentne w kwestii niskiej dokładności swoich narzędzi, mimo że pobierają od użytkowników opłaty w wysokości od 20 do nawet 200 dolarów miesięcznie za dostęp do najnowszych modeli AI. Co więcej, płatne wersje, takie jak Perplexity Pro (20 USD/miesiąc) i Grok-3 Search (40 USD/miesiąc), oferują niewielką poprawę w stosunku do darmowych odpowiedników, przy jednoczesnym wyższym wskaźniku błędów.
Nie wszyscy jednak uważają, że problem niedokładności AI jest aż tak poważny. Lance Ulanoff z TechRadar twierdzi, że po wypróbowaniu ChatGPT Search może już nigdy nie wrócić do Google. Podkreśla on, że narzędzie jest szybkie, świadome i dokładne, a przy tym oferuje czysty interfejs pozbawiony reklam.
Spodobało Ci się? Podziel się ze znajomymi!

Pokaż / Dodaj komentarze do:
Niespodzianka, wyszukiwarki AI są niedokładne i kłamią na potęgę. Grok Elona Muska wypadł najgorzej