

Zapewne większość z nas traktuje AI jako mniej lub bardziej interesującą nowinkę. W wielu zastosowaniach jest naprawdę przydatna, a możliwość przyśpieszenie obliczeń za pomocą układów NPU czy rdzeni Tensor również budzi spore zainteresowanie.
Cześć z nas zamierza jednak dokonywać obliczeń związanych z AI na własnym sprzęcie. Jak sprawdzić wydajność danej konfiguracji w zastosowaniach AI? Wystarczy sięgnąć po odpowiedni benchmark. Ich mocną stroną jest po prostu brak konieczności skomplikowanej konfiguracji - po prostu klikamy i odpalamy test.
Ale zaraz - termin “zastosowania AI” jest bardzo szeroki. Czy chodzi o wydajność uczenia maszynowego przy użyciu dużych modeli językowych (LLM), generowania obrazów, identyfikacji twarzy czy obiektów? Spokojna głowa, w tym artykule dowiecie się również, które benchmarki sprawdzają konkretne zastosowania.
Powiedzmy sobie szczerze, że obecnie nie ma bazyliona benchmarków AI w których możemy przebierać, jednak znajdzie się kilka narzędzi, za pomocą których sprawdzimy wydajność różnych podzespołów (zarówno CPU, GPU, jak i NPU). Zobaczmy jednak z jakich benchmarków możemy skorzystać i jakie mają wymagania sprzętowe.
Darmowe benchmarki do testowania AI
Najpopularniejszą aplikacją tego typu jest oczywiście Geekbench AI (początkowo występował pod nazwą Geekbench ML). Niewielki, niepozorny i prosty w obsłudze, umożliwia wykorzystanie różnych frameworków (ONNX czy OpenVINO) i backendów oraz zaprzęgnięcie do obliczeń CPU, GPU i NPU - z zastrzeżeniem, że na razie nie wszystkie modele NPU są obsługiwane (np. AMD).
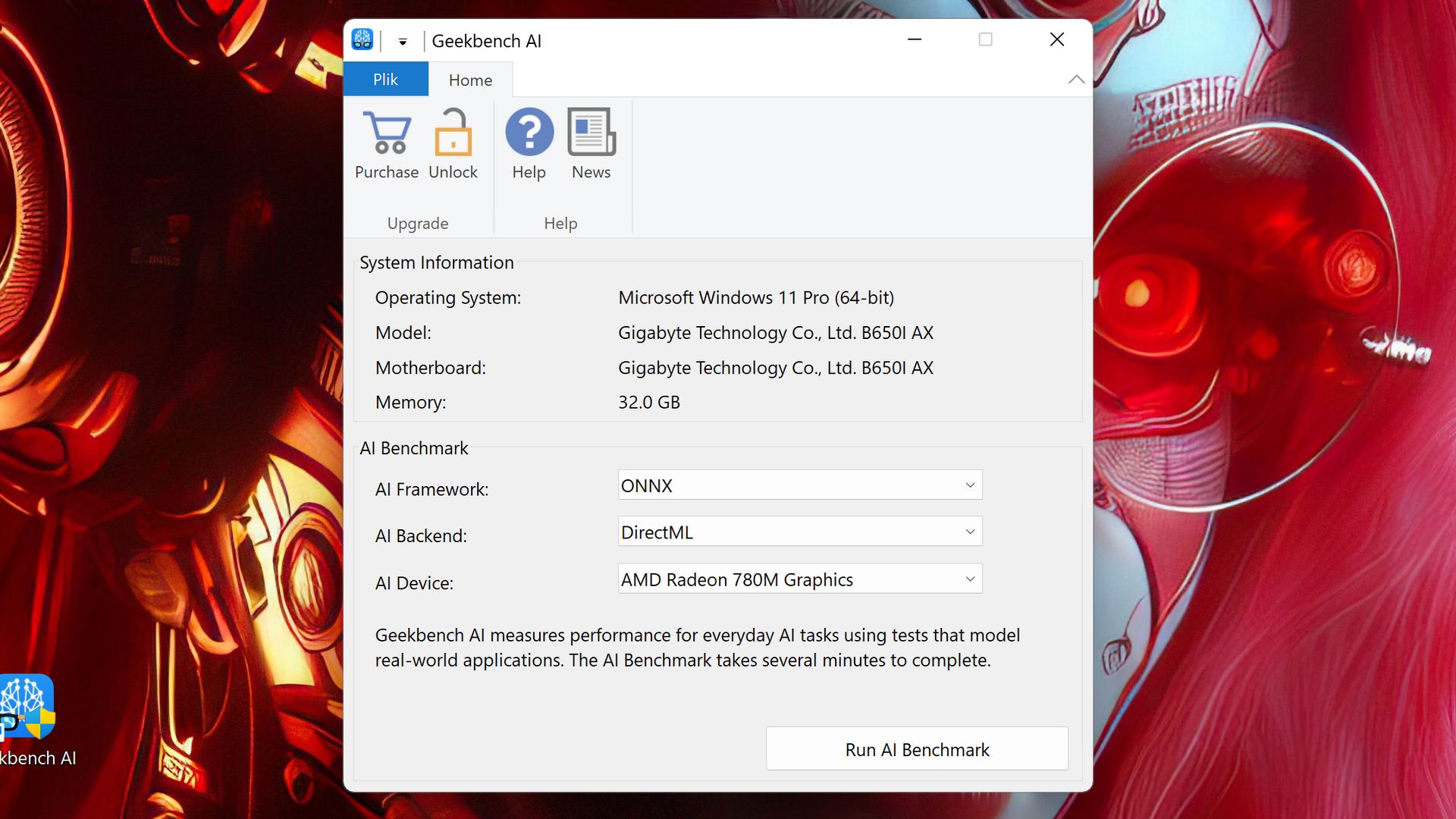
Wystarczy uruchomić test z zadanymi ustawieniami, by po chwili otrzymać zbiorcze wyniki punktowe w Single Precision, Half Precision i Quantized, jak i bardziej szczegółowe wyniki w poszczególnych zastosowaniach.
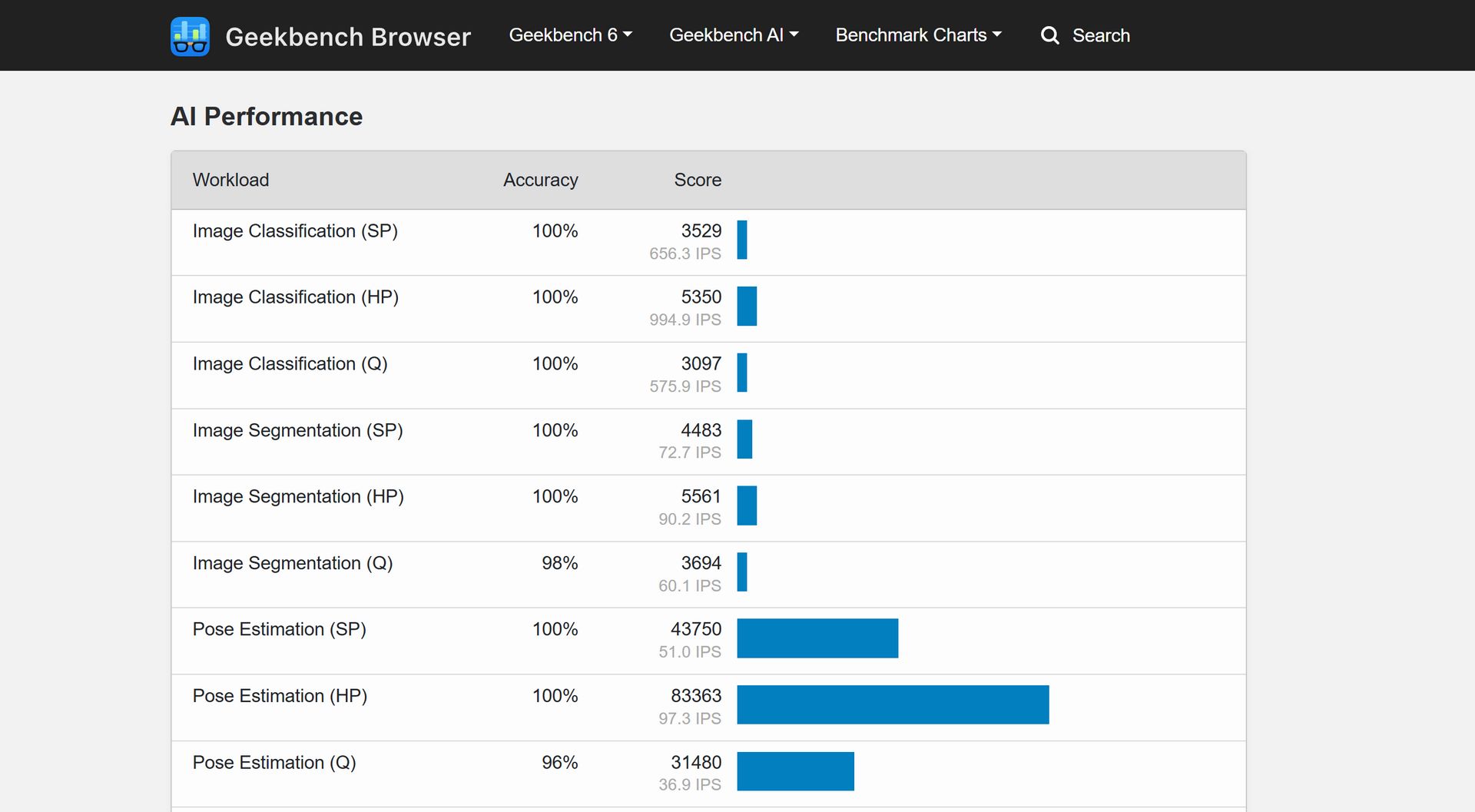
Jakie konkretnie testy przeprowadza Geekbench AI i z użyciem jakich sieci neuronowych?
• Image Classification - identyfikacja kategorii obiektu (MobileNetV1)
• Image Segmentation - identyfikacja różnych obiektów (DeepLabV3+)
• Object Detection - identyfikacja obiektu i jego lokalizacji w przestrzeni (SSD)
• Face Detection - identyfikacja twarzy i lokalizacji w przestrzeni (RetinaFace)
• Pose Estimation - identyfikacja póz ludzkich sylwetek (OpenPoseV2)
• Depth Estimation - tworzenie mapy głębi obrazu (ConvNets)
• Image Super Resolution - konwersja obrazu do wyższej rozdzielczości (RFDN)
• Style Transfer - tworzenie obrazu na podstawie stylu innego obrazu (Image Transform Net)
Minimalne wymagania Geekbench AI są śmiesznie niskie i zadowoli się on praktycznie dowolnym procesorem i 8 GB pamięci operacyjnej (Windows i MacOS), a w niektórych przypadkach nawet 4 GB RAM (Linux).
Całkiem niedawno otrzymaliśmy również w końcu darmową wersję benchmarka MLPerf (Client), który pracuje na dużych modelach językowych. W testach LLM benchmark ten wykorzystuje model Llama 2 7B.
MLPerf sprawdzi dla nas, jak szybko dany sprzęt potrafi wykonywać konkretne zadania związane z uczeniem maszynowym – zarówno jeśli chodzi o fazę treningu modeli, jak i wdrażania. W takich zastosowaniach przetwarza się duże sekwencje danych i realizuje złożone zadania - włączając odpowiedzi na pytania, rozwiązywanie problemów czy wręcz generowanie kodu.
Wyniki otrzymamy w TPS (tokenach na sekundę) i TTFT (czas potrzebny do wygenerowania pierwszego tokena). Jak na razie ten benchmark pozbawiony jest GUI i trzeba go uruchamiać z terminala (np. PowerShell). Szkoda, bo zwiększyłoby to jego popularność - wielu użytkowników dostaje drgawek, gdy widzi aplikację pozbawioną graficznego interfejsu użytkownika.
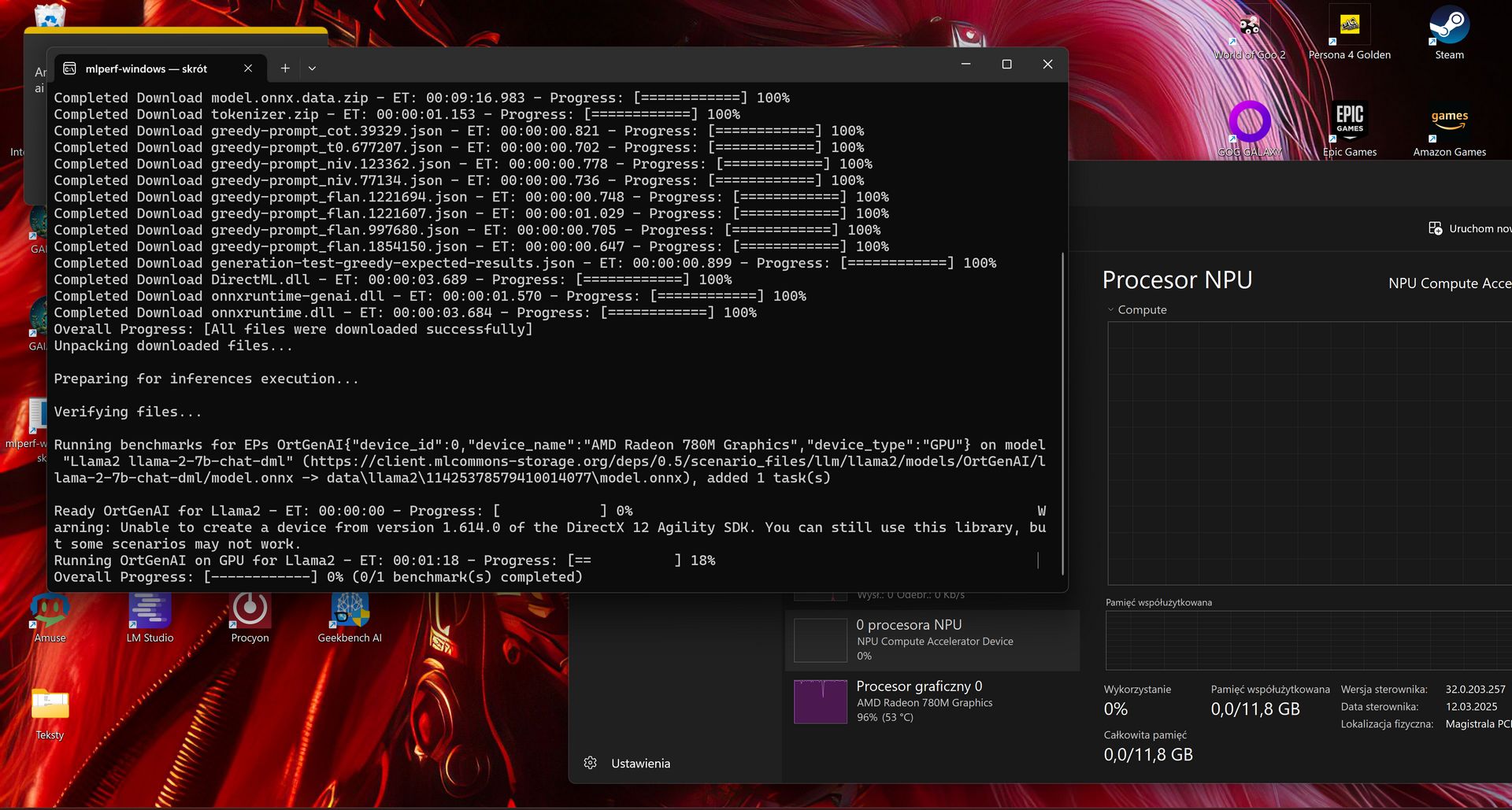
Uruchomienie wymaga wprowadzenia komendy mlperf-windows.exe -c . W miejscu pliku konfiguracyjnego podajemy nazwę jsona (znajdziesz je w archiwum z plikiem wykonywalnym) odpowiedniego dla danej konfiguracji (AMD, Intel lub NVIDIA). Przy pierwszym uruchomieniu oczywiście trzeba się liczyć z koniecznością pobrania modelu.
W obecnej wersji minimalne wymagania MLPerf Client przedstawiają się następująco:
-
AMD: procesory Ryzen AI z 32 GB pamięci systemowej lub karty Radeon 7000 z 16 GB VRAM
-
Intel: procesory Core Ultra 200 z zintegrowaną grafiką Arc z 16 GB pamięci systemowej lub karty Arc z 8 GB VRAM
-
NVIDIA: karty graficzne serii GeForce RTX 4000 z 12 GB VRAM i 16 GB pamięci systemowej
Płatne benchmarki do testowania AI
Tak oto dotarliśmy do absolutnie najlepszego benchmarka AI, który to jest niestety płatny. Miejmy nadzieję, że z czasem producent udostępni darmową (chociaż pewnie ograniczoną) wersję.
Procyon to dzieło twórców doskonale znanego 3D Marka i początkowo miał być benchmarkiem sprawdzającym tylko wydajność w zastosowaniach AI. Jego rozwój poszedł jednak szerzej i obecnie oprócz testów AI oferuje również funkcjonalność PC Marka, bowiem można tu znaleźć testy:
-
Office Productivity Benchmark (test wydajności przy użyciu pakietu MS Office, czy też jak to się obecnie nazywa - MS 365)
-
Video Editing Benchmark (testy przy użyciu Adobe Premiere Pro
-
Photo Editing Benchmark (testy przy użyciu Adobe Photoshop i Lightroom)
-
Battery Life Benchmark (test baterii)
-
One hour battery consumption benchmark (test baterii estymujący wynik na podstawie 1-godzinnego benchmarka)
To tylko tak na marginesie i wróćmy do naszego głównego tematu. Początkowo Procyon miał do dyspozycji tylko jeden test AI, ale obecnie ich liczba wzrosła do trzech. A są to:
-
AI Computer Vision
-
AI Image Generation
-
AI Text Generation
Procyonowi warto poświęcić więcej uwagi, bo jego twórcy wiedzą co robią - to aktualnie najbardziej zaawansowany benchmark do obliczeń związanych z AI. Procyon jest wciąż aktualizowany i ostatnio wzbogacił się o obsługę Ryzen AI w teście AI Compute Vision. Niestety jak na razie wspierane są jedynie układy oparte na XDNA 2.
Procyon - AI Computer Vision
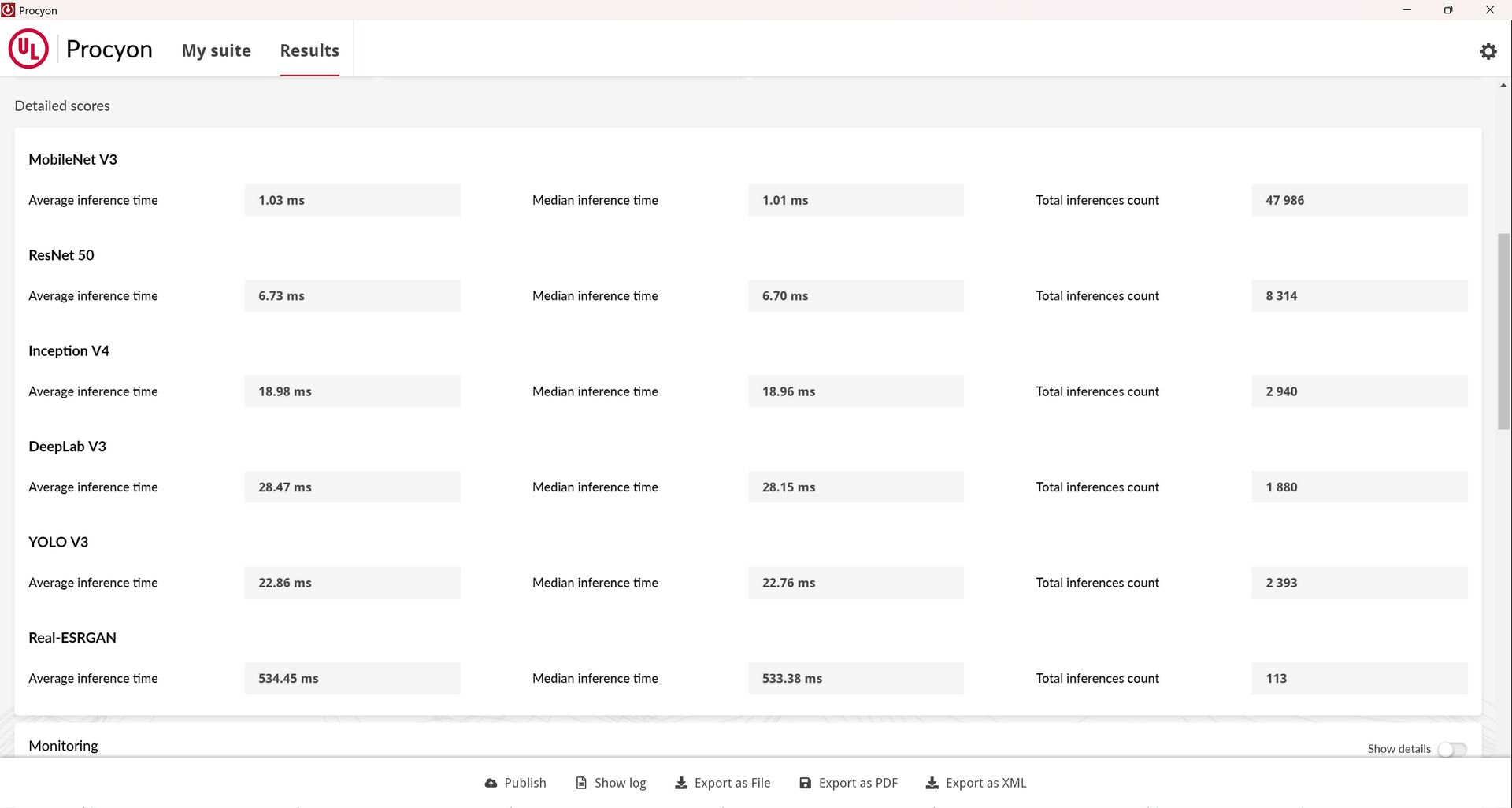
Test ten dostarcza informacji na temat działania silników inferencyjnych AI, co ma pomóc w wyborze wyboru silnika, który pozwoli osiągnąć najlepszą wydajność na danym sprzęcie. Pisząc wprost, sprawdza to sieciach służących do identyfikacji i detekcji obiektów, klasyfikacji obrazów i zwiększania ich rozdzielczości, czyli plus minus działa podobnie do Geekbench AI.
Jakie modele sieci neuronowych wykorzystywane są w tym teście? MobileNet V3, Inception V4, YOLO V3, DeepLab V3, Real-ESRGAN i ResNet 50. Testy można uruchomić zarówno na liczbach zmiennoprzecinkowych (float 32 i 16) jak i całkowitych (integer) na procesorze (CPU), układzie graficznym (GPU), bądź dedykowanym akceleratorze AI (NPU).
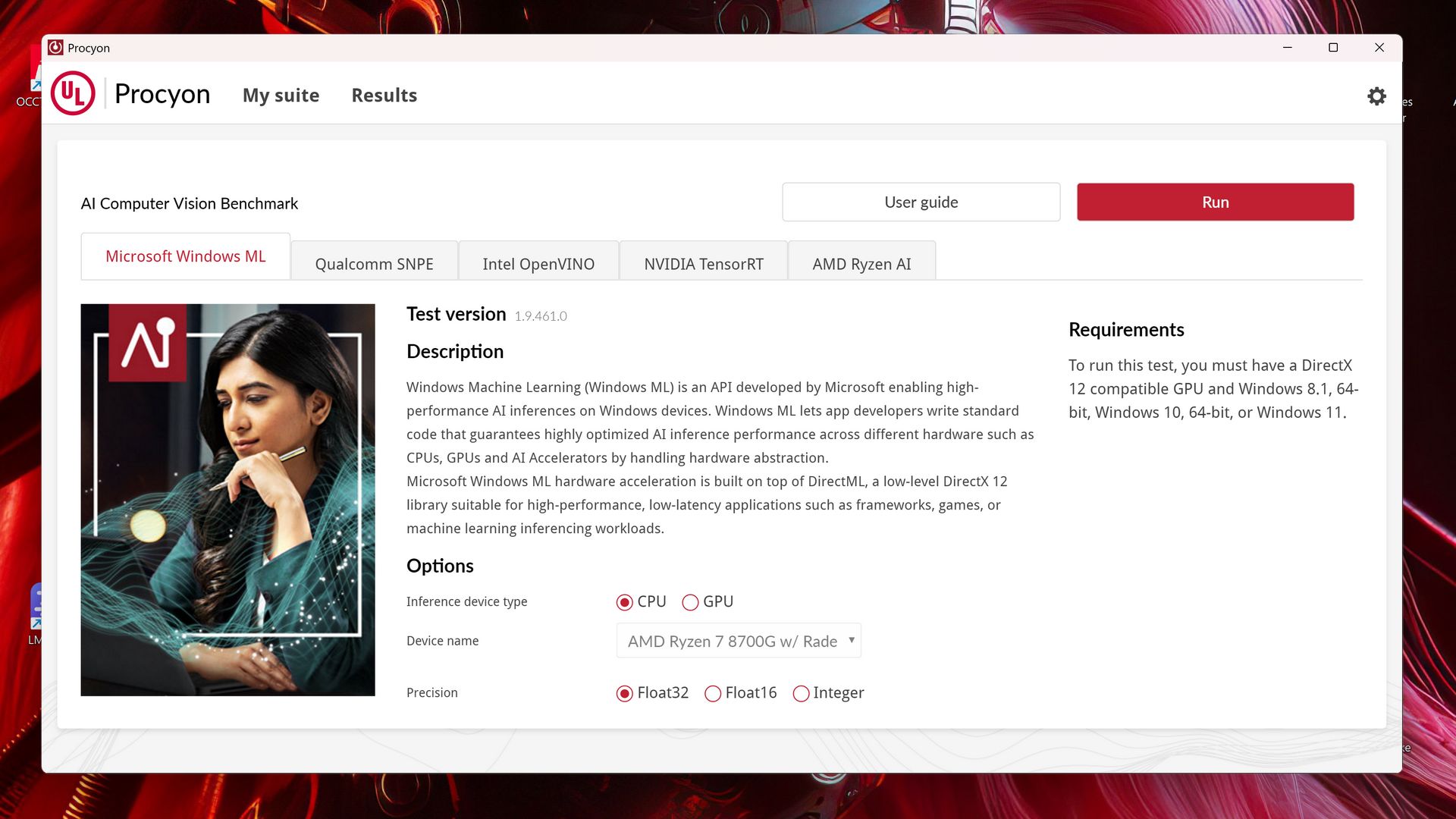
Benchmark pozwala testować wydajność sieci neuronowych zarówno za pomocą Windows ML, NVIDIA Tensor RT, Intel OpenVINO, AMD Ryzen AI (jak na razie brak obsługi pierwszej generacji XDNA), jak i Qualcomm SNPE.
Procyon - AI Image Generation
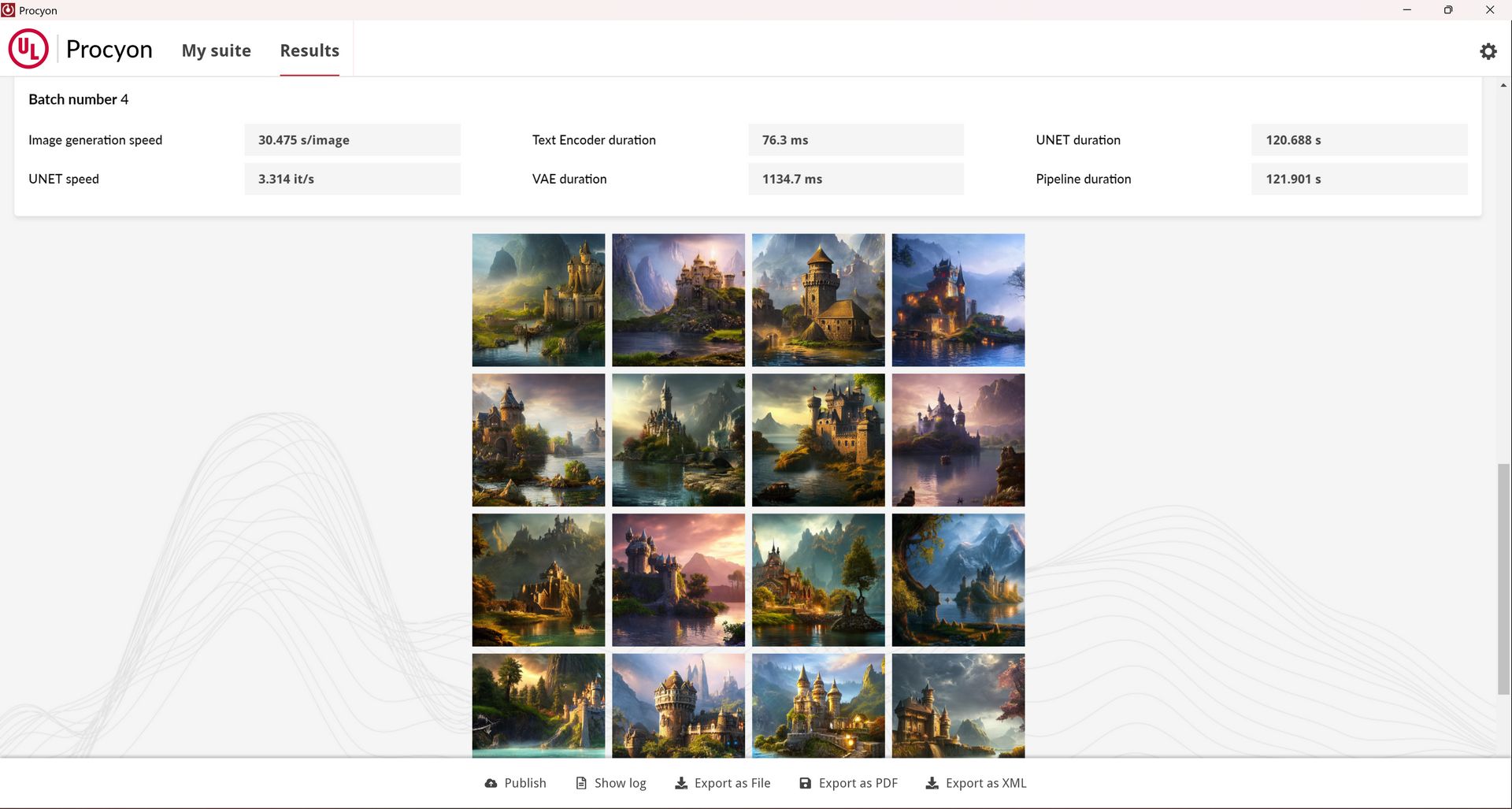
Nazwa tego testu mówi sama za siebie, bo chodzi o oczywiście o generowanie obrazów na podstawie promptów (text to image). Benchmark wykorzystuje różne modele Stable Diffusion - 1.5 (FP16 i FP8) i XL (FP16). Obliczenia są przeprowadzane na GPU/iGPU lub NPU (tylko Stable Diffusion 1.5 INT8).
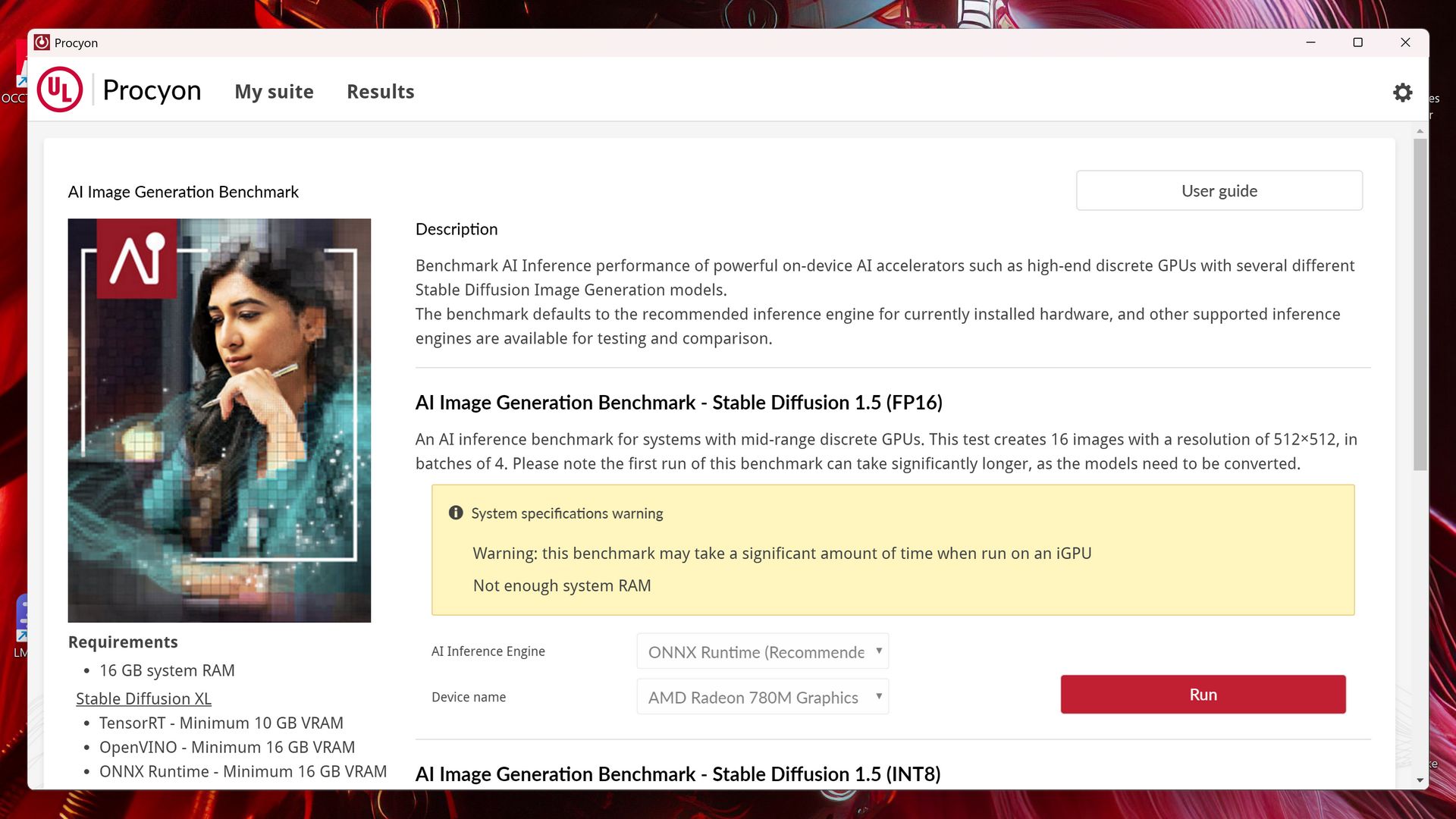
Wymagania są różne, nie tylko w zależności od modelu, ale i wykorzystywanego sprzętu. Generalnie absolutne minimum AI Image Generation to 16 GB pamięci systemowej, ale dochodzi tu jeszcze kwestia pamięci VRAM.
Minimalne wymagania VRAM testu Stable Diffusion XL:
-
Tensor RT - 10 GB VRAM
-
OpenVINO - 16 GB VRAM
-
ONNX - 16 GB VRAM
Minimalne wymagania testu Stable Diffusion 1.5 INT8:
-
Tensor RT - co najmniej karta GeForce serii 3000
-
OpenVINO - NPU Intela lub zintegrowana bądź zewnętrzna karta graficzna Arc
Minimalne wymagania testu Stable Diffusion 1.5 INT16:
-
co najmniej 32 GB pamięci systemowej dla systemów z zintegrowaną grafiką
-
8 GB VRAM dla zewnętrznych kart graficznych
Procyon - AI Text Generation
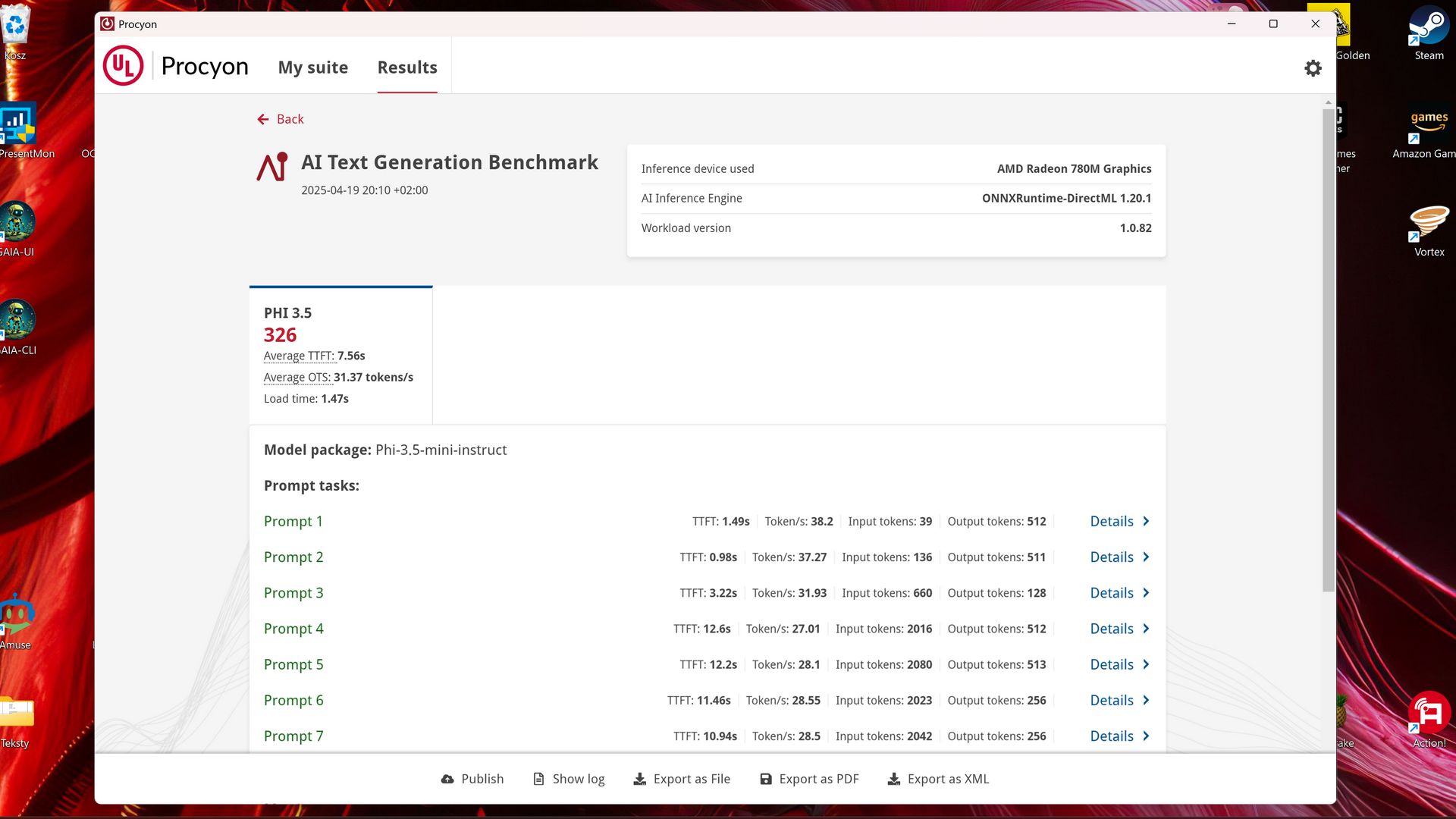
Test ten sprawdza wydajność AI podczas pracy z LLM, ale w odróżnieniu od MLPerf Client pozwala nam skorzystać aż z czterech modeli, a konkretnie: Phi-3.5-mini, Mistral-7B, Llama-3-8B i Llama-2-13B. AI Text Generation wykorzystuje do testów prompty używane w rzeczywistych zastosowaniach (zarówno RAG, jak i non-RAG). Obliczenia przeprowadzane są na GPU/iGPU.
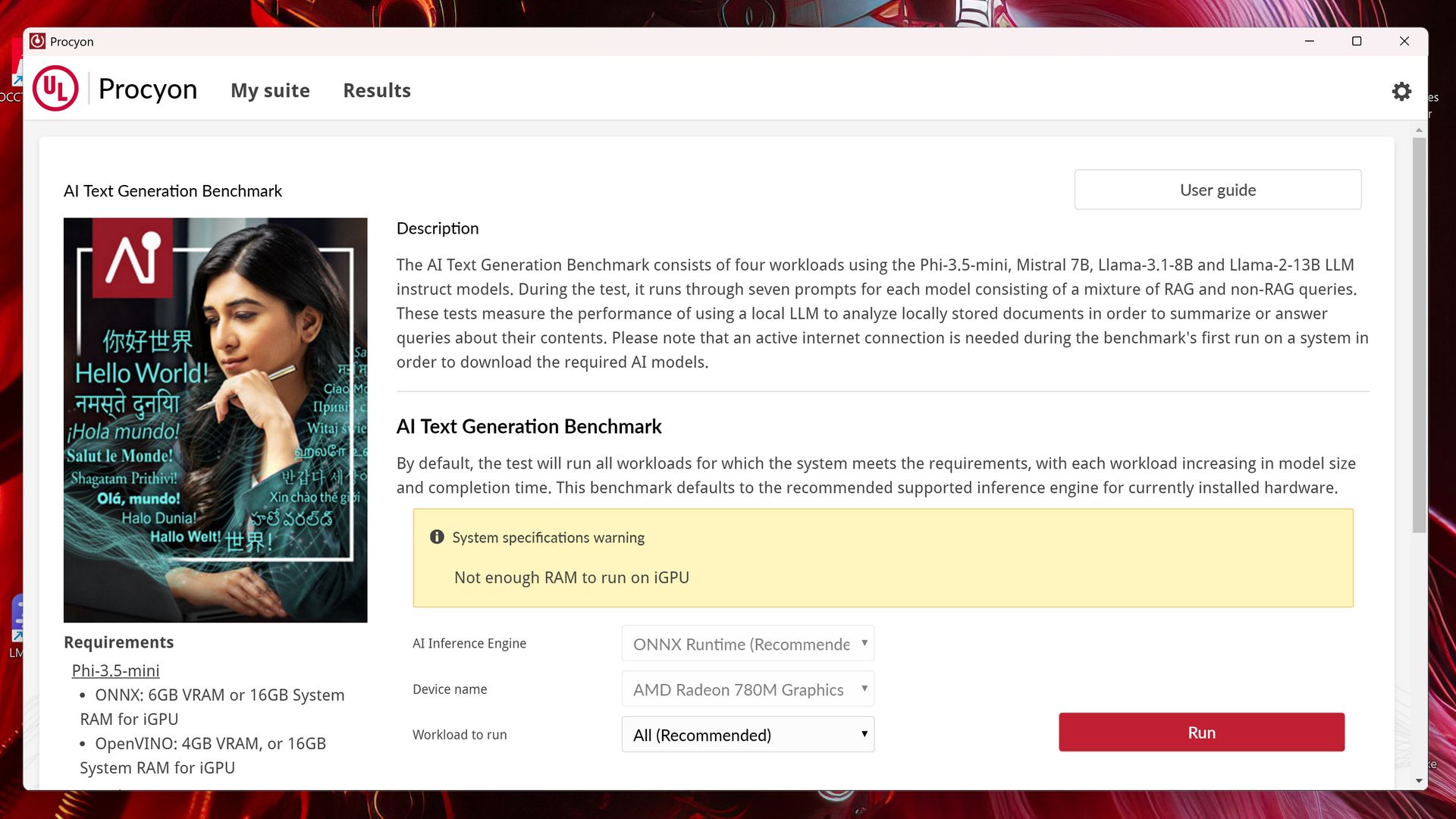
Podobnie jak w przypadku testu AI Image Generation, wymagania różnią się w zależności od modelu i wykorzystanego frameworka:
Minimalne wymagania dla testu Phi-3.5-mini:
-
ONNX - 6 GB VRAM lub 16 GB pamięci systemowej dla iGPU
-
OpenVINO - 4 GB VRAM lub 16 GB pamięci systemowej dla iGPU
Minimalne wymagania dla testu Mistral-7B i Llama-3-8B:
-
ONNX - 8 GB VRAM lub 32 GB pamięci systemowej dla iGPU
-
OpenVINO - 8 GB VRAM lub 32 GB pamięci systemowej dla iGPU
Minimalne wymagania dla testu Llama-2-13B:
-
ONNX - 12 GB VRAM lub 32 GB pamięci systemowej dla iGPU
-
OpenVINO - 10 GB VRAM lub 32 GB pamięci systemowej dla iGPU
Czym sprawdzić wydajność w zastosowaniach AI?
Jeśli nie chcemy sięgać po płatne rozwiązania, a chcemy sprawdzić wydajność sprzętu przy użyciu modelu LLM to możemy wykorzystać MLPerf Client. Jeśli zależy nam na równie darmowym przetestowaniu różnych sieci neuronowych w takich zastosowaniach jak identyfikacja obiektów, czy skalowanie obrazów to możemy skorzystać z Geekbench AI.
Procyon jest bezkonkurencyjny, bowiem pozwala na przetestowanie zarówno różnych modeli LLM, generowania obrazów za pomocą Stable Diffusion, jak i wykorzystanie pozostałych popularnych sieci neuronowych. Trzeba jednak z niego zapłacić, chociaż można spróbować otrzymać dostęp do darmowej wersji próbnej.
Spodobało Ci się? Podziel się ze znajomymi!

Pokaż / Dodaj komentarze do:
Najlepsze benchmarki AI. Czym testować wydajność podzespołów?