
Birentech przedstawiło na Hot Chips 34 kilka nowych szczegółów dotyczących swojego nadchodzącego GPU Biren BR100, który ma być najpotężniejszym chińskim układem graficznym, rzucającym wyzwanie produktom NVIDII i AMD.
GPU Birentech BR100 wykorzystuje autorską architekturę i produkowane jest na bazie 7 nm litografii, a całość składa się łącznie z 77 miliardów tranzystorów. Układ wykorzystuje konstrukcję 2.5D CoWoW firmy TSMC z 300 MB wbudowanej pamięci podręcznej z 64 GB pamięci HBM2e o przepustowości 2,3 TB/s na interfejsie PCIe 5.0 x16 (protokół CXL). Birentech używa dwóch chipletów na swoim GPU BR100, przy czym każdy z zawiera 16 SPC (klastrów przetwarzania strumieniowego). BR100 ma TDP 550 W i jest dostarczany w module OAM.

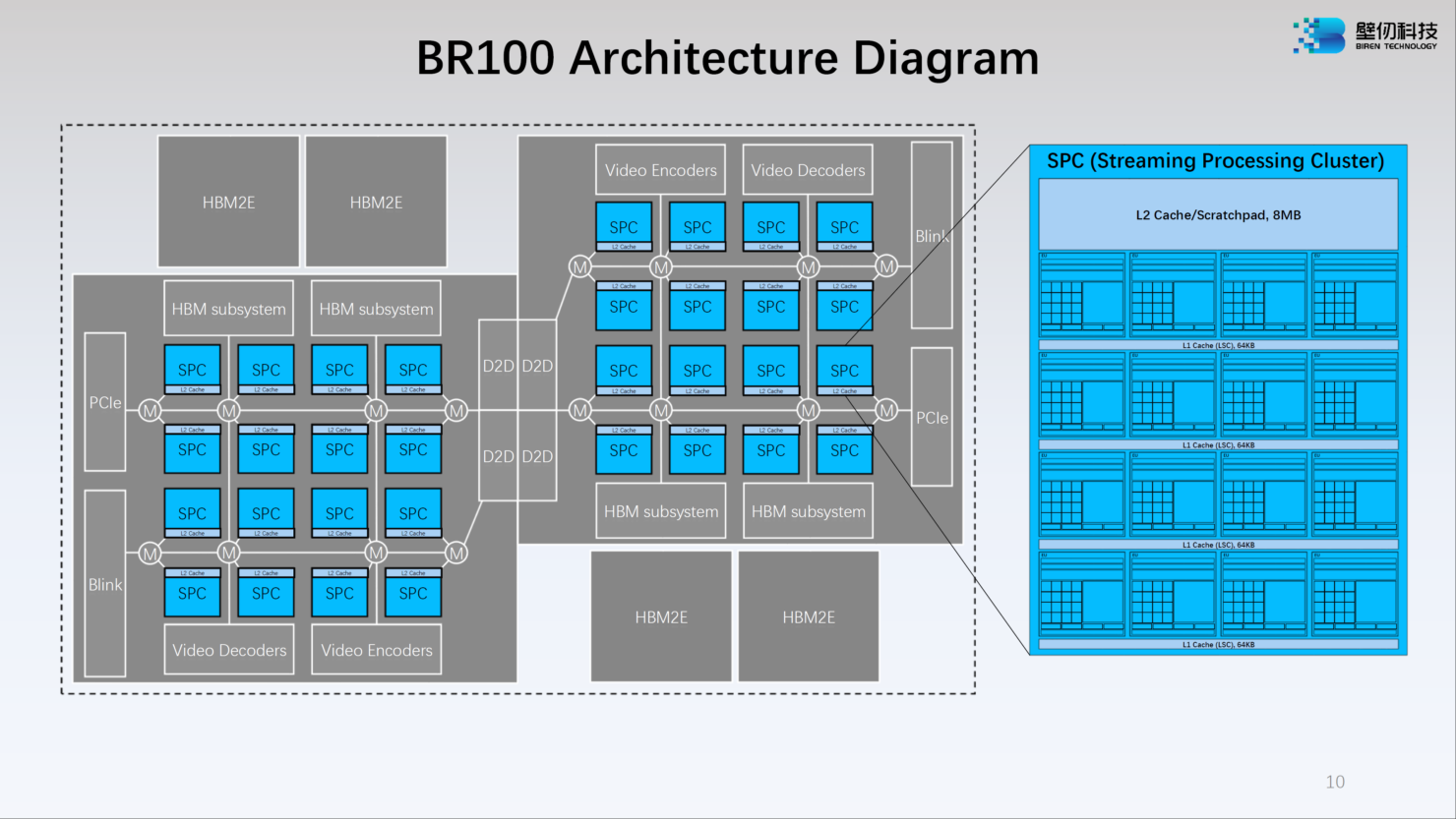
Każdy z SPC ma 16 jednostek wykonawczych (EU), przy czym 4 EU tworzą wewnętrzną jednostkę obliczeniową (CU), która ma 64 KB pamięci podręcznej L1 (LSC), a ponadto SPC współdzieli 8 MB pamięci podręcznej L2 w ramach wszystkim jednostek wykonawczych (EU). W sumie BR100 ma 32 SPC z 512 EU, 256 MB pamięci podręcznej L2 i 8 MB pamięci podręcznej L1.

Podczas Hot Chips 34 Birentech zaprezentował schemat architektury BR100, na którym widać, że jednostka wykonawcza ma 16 rdzeni przetwarzania strumieniowego (V-Core) i jeden silnik Tensor (T-Core)… co nasuwa skojarzenia z GPU NVIDII. Birentech ma 40 KB TLR (Thread Local Register), 4 SFU i TDA (Tensor Data Accelerator).
Każda z jednostek CU może pomieścić łącznie 4, 8 lub do 16 jednostek UE. Nowe GPU BR100 od Birentech i jego V-Core to uniwersalny procesor SIMT z 16 rdzeniami, który obsługuje FP32, FP16, INT32 i INT16. Dostępne jest również wsparcie dla SFU, ładowania/przechowywania i przetwarzania danych, z operacjami głębokiego uczenia wykonywanymi w postaci Batch Norm, ReLu i innych. Ponadto BR100 zawiera ulepszony model SIMT, który jest w stanie uruchomić do 128 tys. wątków na 32 SP w trybie superskalowania (statycznym i dynamicznym). Rdzenie T-Core zostały zaprojektowane z myślą o przyspieszeniu zadań opartych na sztucznej inteligencji, takich jak MMA, Convulution itp.
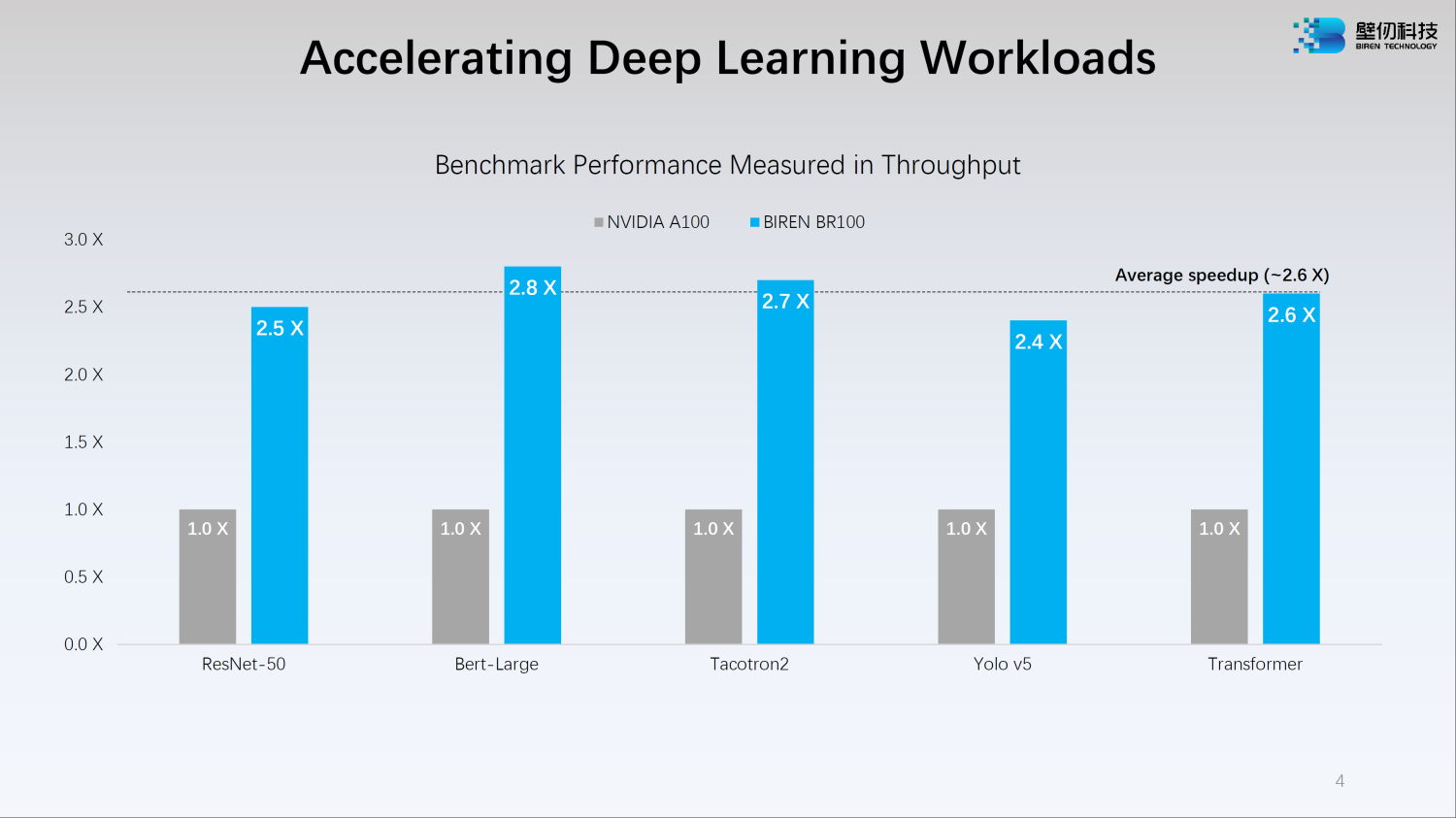
Birentech porównuje swój nowy procesor graficzny BR100 z Ampere A100, czyli profesjonalnym GPU obecnej generacji od NVIDII (firma właśnie przedstawiła swój procesor graficzny nowej generacji Hopper H100, który jest znacznie lepszy). W tych testach BR100 bije GPU Ampere A100 (choć lepiej poczekać na niezależne testy). BR100 pokonuje A100 w wielu obciążeniach HPC, osiągając 2,5-krotnie wyższą wydajność niż A100.
Choć Hopper H100 jest już na horyzoncie, to nowy układ graficzny BR100 firmy Birentech i tak robi wrażenie. NVIDIA ma 80 miliardów tranzystorów tworzących GPU Hopper H100, Birentech ma 77 miliardów tranzystorów wewnątrz BR100. BR100 jest zbudowany na 7 nm, z kolei H100 bazuje na 4 nm (ulepszony 5 nm proces, zoptymalizowany przez TSMC dla NIVDII i H100).
Zobacz także:
- Oracle pozwane za gromadzenie i sprzedaż danych osobowych miliardów osób
- Poznaliśmy datę tzw. scalenia Ethereum. To koniec kopania na kartach graficznych
- Inżynier Apple ds. autonomicznych samochodów przyznał się do kradzieży technologii na rzecz Chin








Pokaż / Dodaj komentarze do: Biren BR100 to pierwsze chińskie GPU, które na poważnie rzuca wyzwanie NVIDII. Znamy szczegóły