

Można być sceptycznym wobec obecnych możliwości rozwiązań AI, ale faktem jest, że korzystamy z nich coraz częściej. Może duże modele językowe jeszcze nie działają idealnie, ale sprawdzają się coraz lepiej i ich popularność będzie wciąż rosła.
Modele LLM działające online mają jednak zasadniczą wadę. Praktycznie wszystko co robimy za ich pomocą, wszystkie dane które do nich wprowadzimy, służą do dalszego szkolenia modelu i generalnie przestajemy mieć na nimi kontrolę. Nasze prywatne dane przestają być naszymi prywatnymi danymi, a ostatnie wydarzenia pokazały, że sytuacja może stać się jeszcze gorsza - bo zapisy naszych konwersacji z botami AI mogą po prostu wylądować w przeglądarce i każdy będzie miał do nich dostęp. Nie wyobrażam sobie pracy nad ważnym projektem, którego szczegóły może poznać dowolna osoba z dostępem do internetu.
Czy to znaczy, że mamy całkowicie zrezygnować z modeli LLM, ze względu na poufność i prywatność? Można zaufać ustawieniom chatbotów, dzięki którym ustalamy, czy nasze dane mają posłużyć szkoleniu modelu, bądź po prostu uruchomiać LLM lokalnie, czyli na własnym komputerze.
AMamy do dyspozycji mnóstwo pewnych i otwartoźródłowych rozwiązań (choćby Mistral AI), z których możemy korzystać bez obawy, że nasze tajne plany podbicia świata przy pomocy AI wyjdą na jaw.
Duże modele językowe (LLM) offline
Sposobów na używanie AI offline jest generalnie sporo, ale w tym przypadku mówimy o LLM i czatbotach działających lokalnie - wykorzystujących do obliczeń GPU, CPU i NPU.
Kwestię wykorzystania NPU pozostawię bez głębszego komentarza, bo wciąż działa to tylko w określonych przypadkach i na konkretnym sprzęcie. To, że twój CPU posiada NPU, nie oznacza jeszcze, że na pewno będziesz mógł go wykorzystać do lokalnego działania LLM. Oczywiście NPU to kwestia która dotyczy głównie posiadaczy laptopów i tam ten układ ma największy sens (bo wykona pracę szybciej niż CPU i zużywając mniej energii niż GPU), ale użytkownicy desktopów z wydajnymi kartami graficznymi i tak dokonają obliczeń znacznie szybciej dzięki GPU, a kwestia dłuższej pracy na baterii ich nie dotyczy.
Podstawowym sprzętem do przetwarzania AI pozostaje więc GPU, a w ekstremalnych przypadkach (czyli np. na układach graficznych z małą ilością VRAM) - CPU.
LM Studio - AI na twoim komputerze, a nie w chmurze
Jednym z popularniejszych narzędzi do używania dużych modeli językowych offline jest LM Studio. LM Studio to proste w użyciu narzędzie, które generalnie powstało dla użytkowników, którzy chcą uruchamiać LLM lokalnie, a nie chcą się bawić w czasochłonne konfiguracje.
Program generalnie jest prosty w użyciu, chociaż czasami głębsza konfiguracja działania modelu (np. działanie hybrydowe przy wnioskowaniu, czy też wykorzystanie konkretnego podzespołu), może wymagać dodatkowych kombinacji.
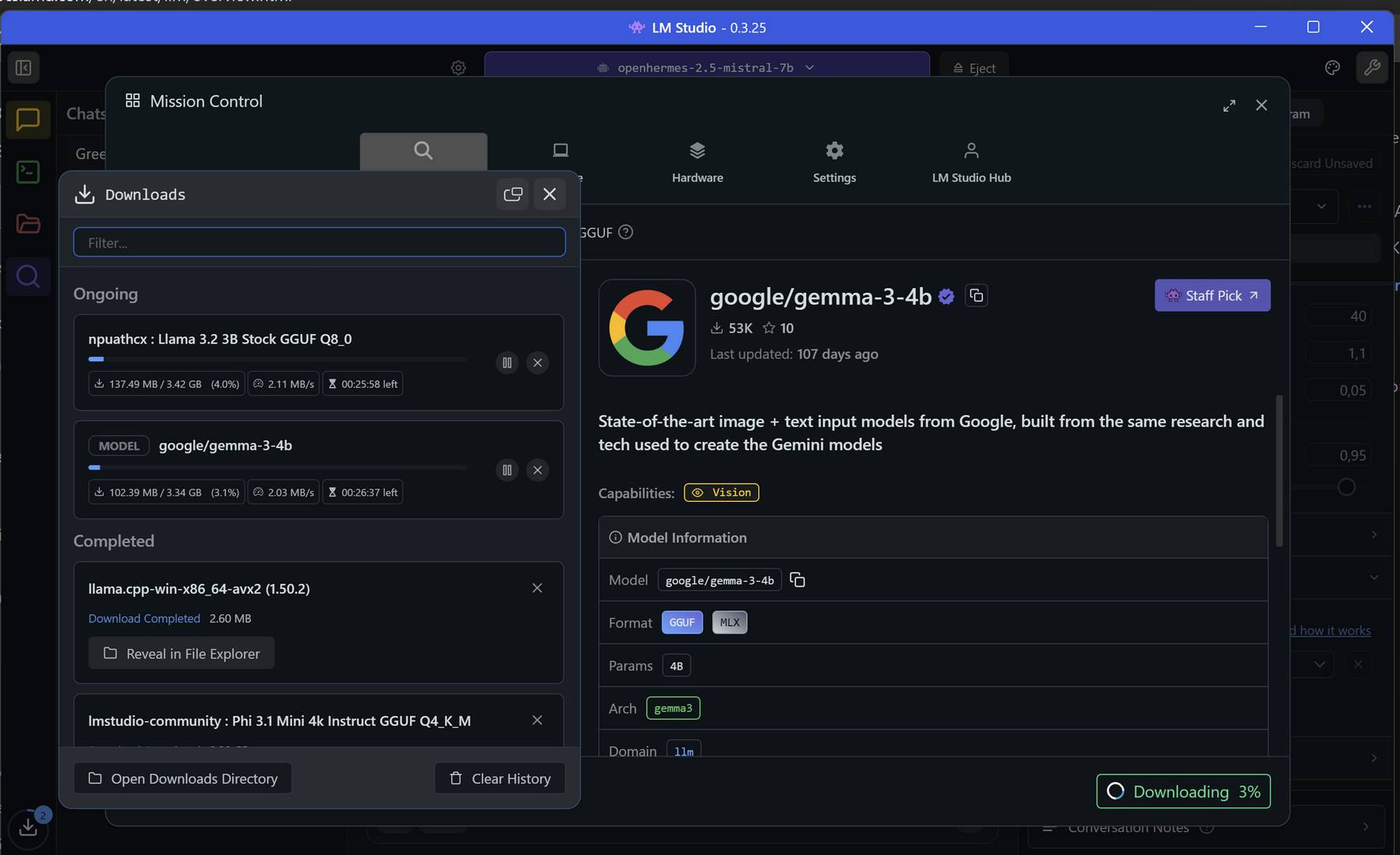
Na start wystarczy wskazać wybrany model LLM (wyszukiwarka jest zintegrowana z programem), pobrać go i działać. Ale chwileczkę… jaki model LLM wybrać?
Wybór modelu LLM - 7B, 4K i Q6 - o co w tym wszystkim chodzi?
Gdy przychodzi do wyboru modeli, to nagle okazuje się, że jest ich co najmniej bazylion, a ich nazwy zawierają wiele oznaczeń. Modele LLM różnią się między sobą parametrami, ale co one oznaczają i jak je identyfikować?
-
Liczba parametrów (B) - określana w miliardach, czyli np. 7B (7 miliardów), czy 13B (13 miliardów). To liczba zmiennych w sieci neuronowej, które model wykorzystuje do przetwarzania danych i generowania odpowiedzi. Im większa - tym model jest bardziej zaawansowany i ma lepszą możliwość “rozumowania”, ale i ma większe wymagania sprzętowe.
-
Długość kontekstu (K) - liczba tokenów (np. słów) które model może przetwarzać równocześnie w trakcie rozmowy lub analizy tekstu. Np. oznaczenie 4K oznacza, że model wykorzystuje maksymalnie 4000 tokenów w jednym zapytaniu i jest do nich ograniczony choćby w trakcie analizy tekstu - nie nadaje się więc do analizowania długich artykułów czy książek.
-
Kwantyzacja (Q) - kompresja modelu, która zmniejsza wymagania sprzętowe, (zazwyczaj) zwiększa szybkość działania, ale zarazem obniża jego precyzję (dokładność modelu). Wartość Q4/Q5 oznacza balans pomiędzy szybkością działania, a jakością odpowiedzi. Generalnie kwantyzacja pozwala na bardziej efektywne wykorzystywanie zasobów sprzętowych i uruchamianie LLM na sprzęcie, który normalnie nie pozwoliłby na obsługę modelu o takich możliwościach.
Modeli jest mnóstwo i przed ich wykorzystaniem warto poznać ich wymagania i mocne strony. Jeśli jednak mielibyśmy zaproponować przykładowe modele to:
-
Domowy komputer o małej wydajności - Phi-3 Mini (3.8B)
-
Przeciętny domowy komputer - Mistral 7B czy Gemma 2 9B
-
Bardzo wydajny domowy komputer z potężną kartą graficzną (np. GeForce RTX 5090 z 32 GB VRAM) - do wszechstronnych zadań Llama 3.1 70B Instruct lub Qwen 3 72B, do programowania CodeLlama 70B (Q4_K_M), a dla zaawansowanych modeli eksperymentalnych Mixtral 8x22B Instruct (Q4_K_M).
Oczywiście nic nie stoi na przeszkodzie, by do LM Studio załadować polskiego Bielika.
Mam kiepskie GPU, ale chcę uruchamiać LLM lokalnie
W przypadku mało wydajnych GPU z małą ilością VRAM (lub zintegrowanych rozwiązań przy małej pojemności dedykowanej pamięci) próba załadowania modelu może kończyć się enigmatyczną informacją o błędzie. LM Studio bowiem domyślnie będzie próbować wykorzystywać akcelerację Vulkan (GPU) na układach graficznych Radeon.
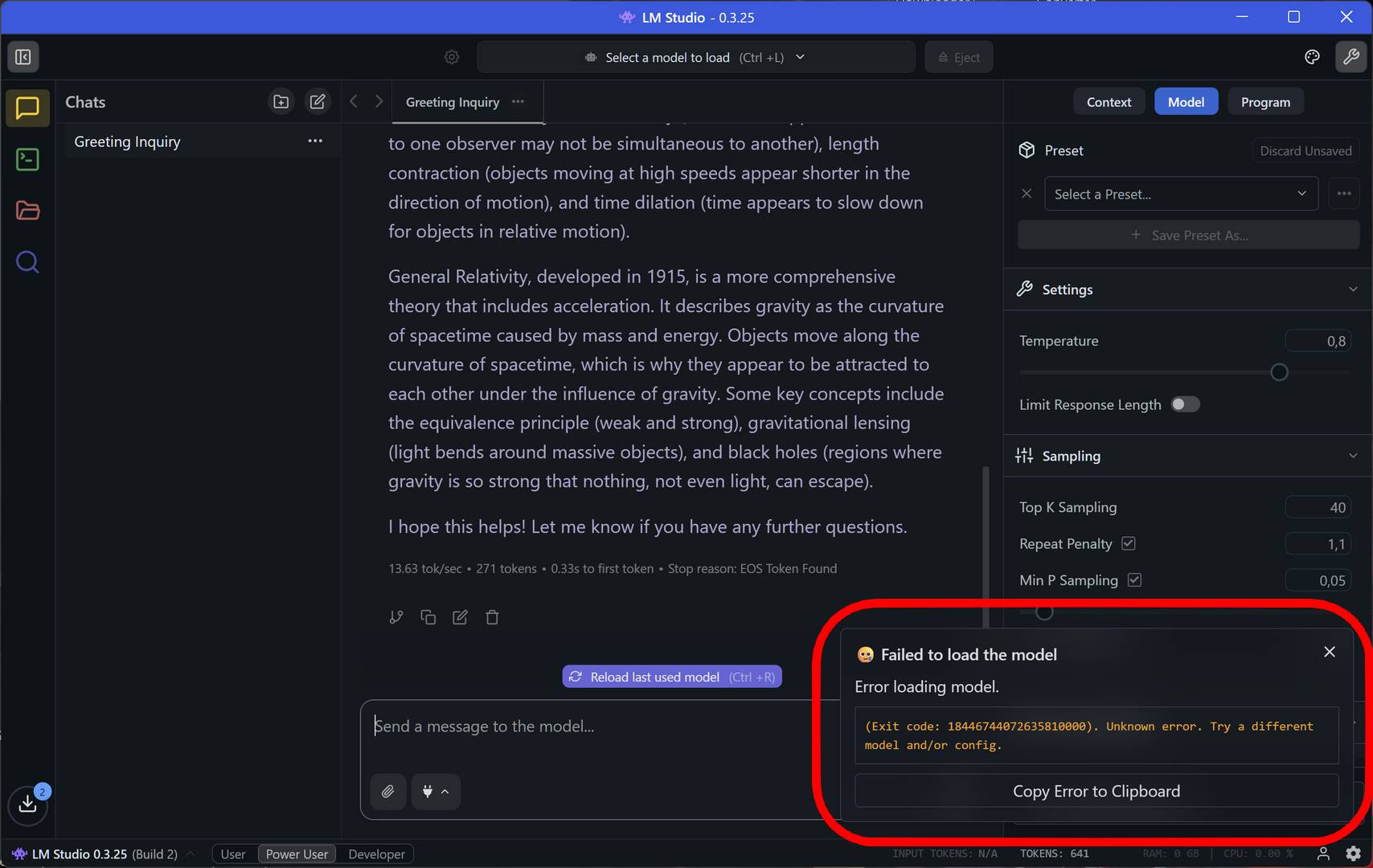
Problem może dotyczyć również słabszych układów GeForce, które mogą mieć problem z wykorzystaniem CUDA. W takim przypadku wystarczy przestawić działanie modelu (Runtime) na CPU. Nie będzie działać to super wydajnie, ale cóż… przynajmniej będzie działać w ogóle.
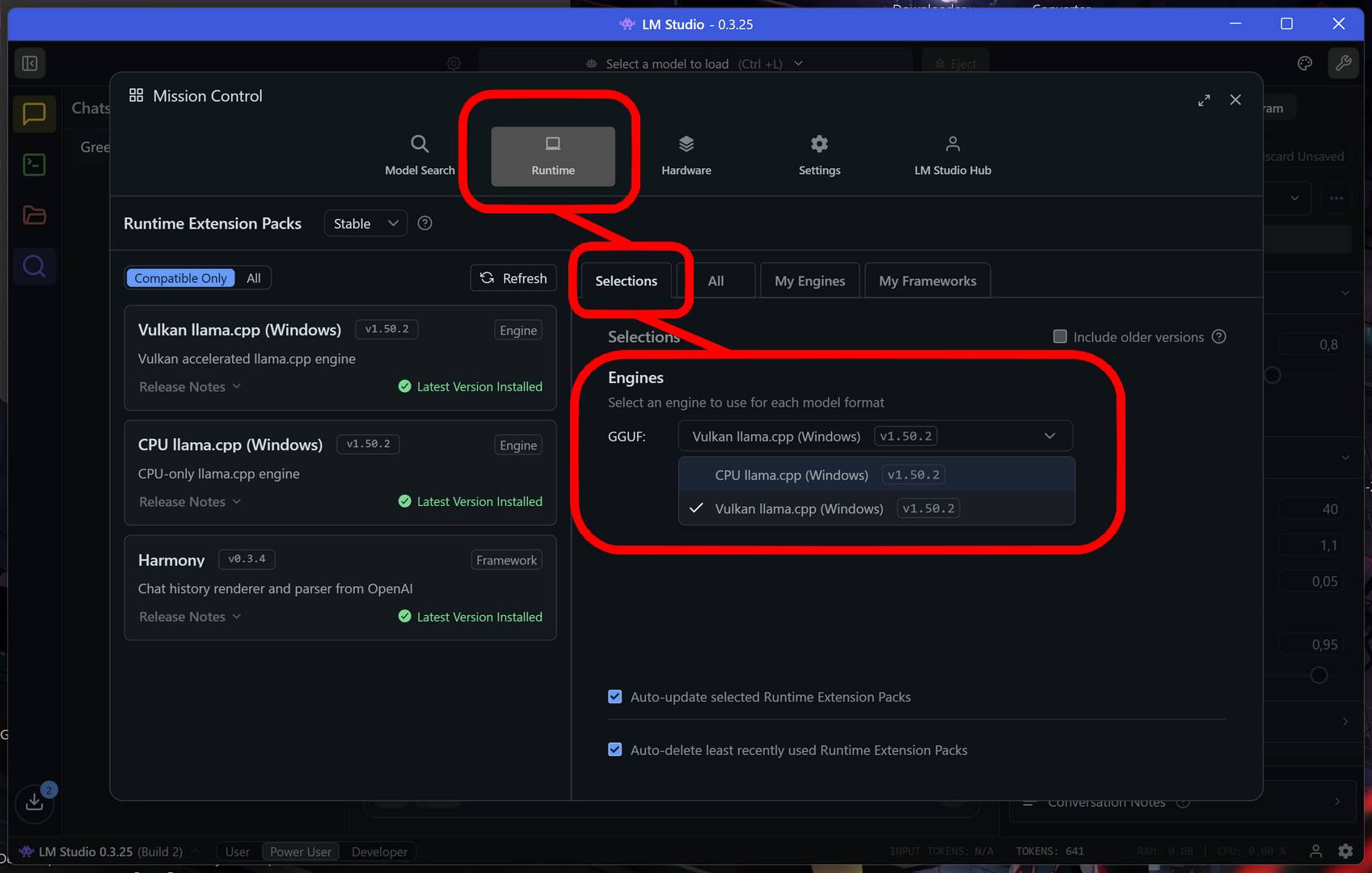
Jak wspomniałem powyżej, trzeba przede wszystkim brać pod uwagę, że LLM wymagają sporo pamięci i wybrać taki model, który będzie można uruchomić na naszej konfiguracji.
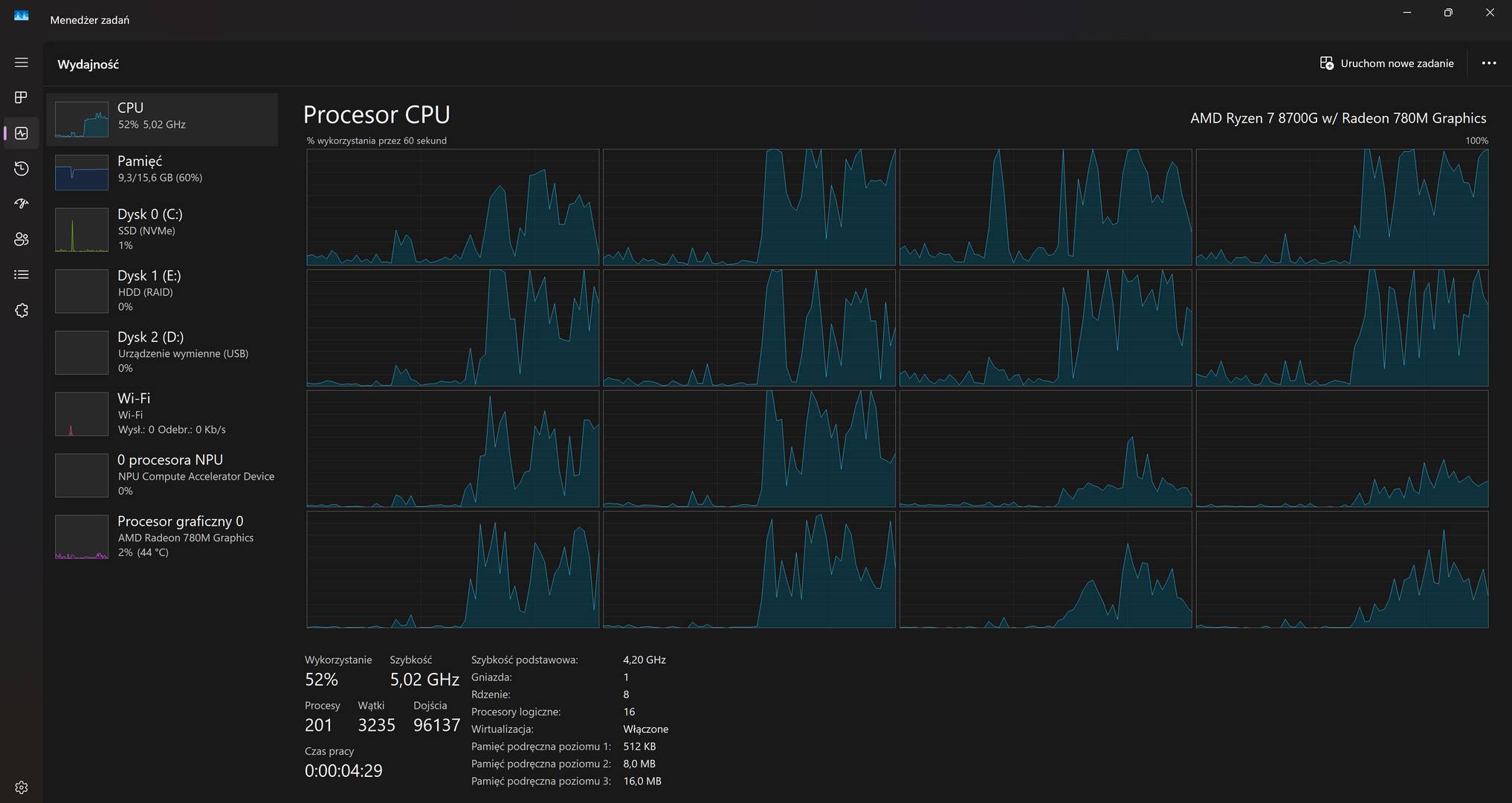
Konfiguracja modelu pozwoli nam wybrać, z ilu rdzeni procesora ma on korzystać, jak i ustawić wiele innych parametrów.
Alternatywy dla LM Studio
Jeśli LM Studio niespecjalnie ci odpowiada, poniżej zamieszczamy jeszcze alternatywy stworzone pod konkretny sprzęt:
-
Posiadacze kart GeForce RTX powinni w pierwszej kolejności sięgnąć po NVIDIA ChatRTX. Oprogramowanie po prawdzie wciąż jest w wersji beta (v0.5), ale się rozwija. Wymagania: GPU - GeForce RTX 5090 lub 5080, lub GeForce RTX z serii 30 albo 40 z co najmniej 8 GB pamięci VRAM. RAM - 16 GB lub więcej.
-
Posiadacze kart (lub zintegrowanych układów) Intel Arc powinni sięgnąć po Intel AI PlayGround. Wymagania: GPU - Arc serii A i B z co najmniej 8 GB VRAM. CPU - Intel Core Ultra 200H (ARL-H), Intel Core Ultra 200V (LNL) lub Intel Core Ultra 100H (MTL-H).
-
Posiadacze procesorów Ryzen AI mogą sięgnąć po AMD Gaia, ale oprogramowanie wciąż jest na wczesnym etapie rozwoju. Wymagania: CPU - Ryzen AI 300 dla trybu hybrydowego (NPU+GPU) lub dowolny procesor Ryzen dla pozostałych (Vulkan/CPU mode).
Lokalnie, ale nie do końca
Na koniec warto zahaczyć o kwestię prywatności chińskich modeli, takich jak DeepSeek R1. W sieci można znaleźć materiały dowodzące, że model DeepSeek łączy się z chińskimi serwerami. Jakie konkretnie dane na nie wysyła - nie wiadomo, ale warto mieć to na uwadze, jeśli już decydujesz się na wykorzystanie DeepSeek.
Spodobało Ci się? Podziel się ze znajomymi!

Pokaż / Dodaj komentarze do:
Uruchamiaj modele AI lokalnie. Przetestowałem duże modele językowe w LM Studio