

Klientów do lokalnej obsługi AI może i nie brakuje, ale trudno wymienić jedno rozwiązanie, które zdobyło dużą popularność. Wszystko co działa online - jak ChatGPT, Copilot czy Gemini - jest dobrze rozpoznawalne i używane przez miliony ludzi na co dzień. W przypadku rozwiązań działających lokalnie sprawa wygląda inaczej, niby jakieś są dostępne, ale w praktyce - poza kręgiem osób specjalizującym się temacie - ich rozpoznawalność jest niska.
Modele AI działające online mają wiele zalet i jeszcze więcej wad. Przede wszystkim nawet jeśli są one udostępnione za darmo, to ich możliwości są ograniczane, bądź spowalniane przez dostawców. Co z tego, że ChatGPT otwiera swoje nowe możliwości nawet w darmowej wersji, jeśli pozwoli ci stworzyć trzy obrazki dziennie, a po piątym zapytaniu zaczyna cedzić odpowiedź słowo po słowie, a po dziesiątym literka po literce.
Jeśli chcesz żeby AI online zawsze działało sprawnie i pełną parą, to musisz po prostu zapłacić abonament. Awaria usługi czy internetu całkowicie odcina nas od pomocy AI. Może nie zdarza się to często, ale takie ryzyko zawsze istnieje. Jest też oczywiście kwestia prywatności - nie chcemy wysyłać AI w chmurze naszych prywatnych pomysłów, czy poufnych danych, bo szybko mogą zmienić status na publiczne i ogólnodostępne. No i chcielibyśmy w końcu zaprząc do pracy NPU w naszych procesorach, prawda?
Oczywiście można sobie po prostu zainstalować LM Studio, wybrać interesujący LLM i działać offline, ale… po kilku eksperymentach z różnymi modelami nie udało mi się zaprząc do akcji NPU w moim procesorze (APU Phoenix). Poza tym niektóre modele potrafią się wykrzaczać, a ich prawidłowa konfiguracja czasami wymaga nurkowania po różnych forach w poszukiwaniu pomocy. Czasami przypomina to instalację na Linuksie niewspieranej drukarki i jest tak samo “zabawne” i czasochłonne.
AI lokalnie
Jeśli szukacie lokalnego agenta AI, to posiadacze kart GeForce RTX (co najmniej serii 3000 z 8 GB VRAM) mogą sięgnąć po NVIDIA ChatRTX, a posiadacze procesorów (Core Ultra) i kart graficznych Intela (Arc serii A i B) mają do dyspozycji Intel AI Playground. Zarówno rozwiązania od Intela, jak i NVIDII, pomimo wczesnych wersji działają całkiem sprawnie i są one proste w obsłudze.
A co u AMD? Pierwsze procesory z NPU (XDNA), czyli AMD Phoenix zadebiutowały w 2023 r. Aktualnie modele Ryzen AI 300 wyposażone są w XDNA 2 i oferują już znacznie wyższą wydajność, mieszczącą się w wymaganiach programu Copilot+. Równocześnie pierwsza generacja NPU została nieco zapomniana i nawet takie benchmarki do testowania AI jak Procyon, potrafią wykorzystać tylko XDNA 2. GeekBench AI wciąż w ogóle nie wykorzystuje NPU AMD.
Ale oto promyk nadziei - “Czerwoni” zaprezentowali właśnie swojego lokalnego agenta AI, o nazwie AMD GAIA. Czego można się po nim spodziewać i czy w końcu będę mógł wykorzystać NPU w moim procesorze?
AMD Gaia - lokalny agent AI dla APU
Co w ogóle potrafi AMD GAIA? Umożliwia działanie aplikacji opartych na LLM w modelu hybrydowym (NPU+GPU) co teoretycznie powinno zapewnić najwyższą możliwą wydajność na domowym sprzęcie, bez konieczności korzystania z chmury. Można ją wykorzystać na wiele sposobów - od rozmów z AI, przez aplikacje z RAG (Retrieval-Augmented Generation), po tworzenie własnych agentów. Możliwa jest obsługa przez GUI, jak i CLI.
GAIA występuje w dwóch wersjach: ogólnej (Generic) i hybrydowej (Hybrid). To właśnie druga umożliwia równoczesne wykorzystanie iGPU i NPU, ale uwaga - jak na razie tylko na procesorach Ryzen AI 300. Oczywiście nie powstrzymało mnie to od prób włączenia do akcji NPU w moim procesorze. Wersja ogólna może być uruchamiana zarówno na starszych procesorach AMD, jak i procesorach innych producentów.
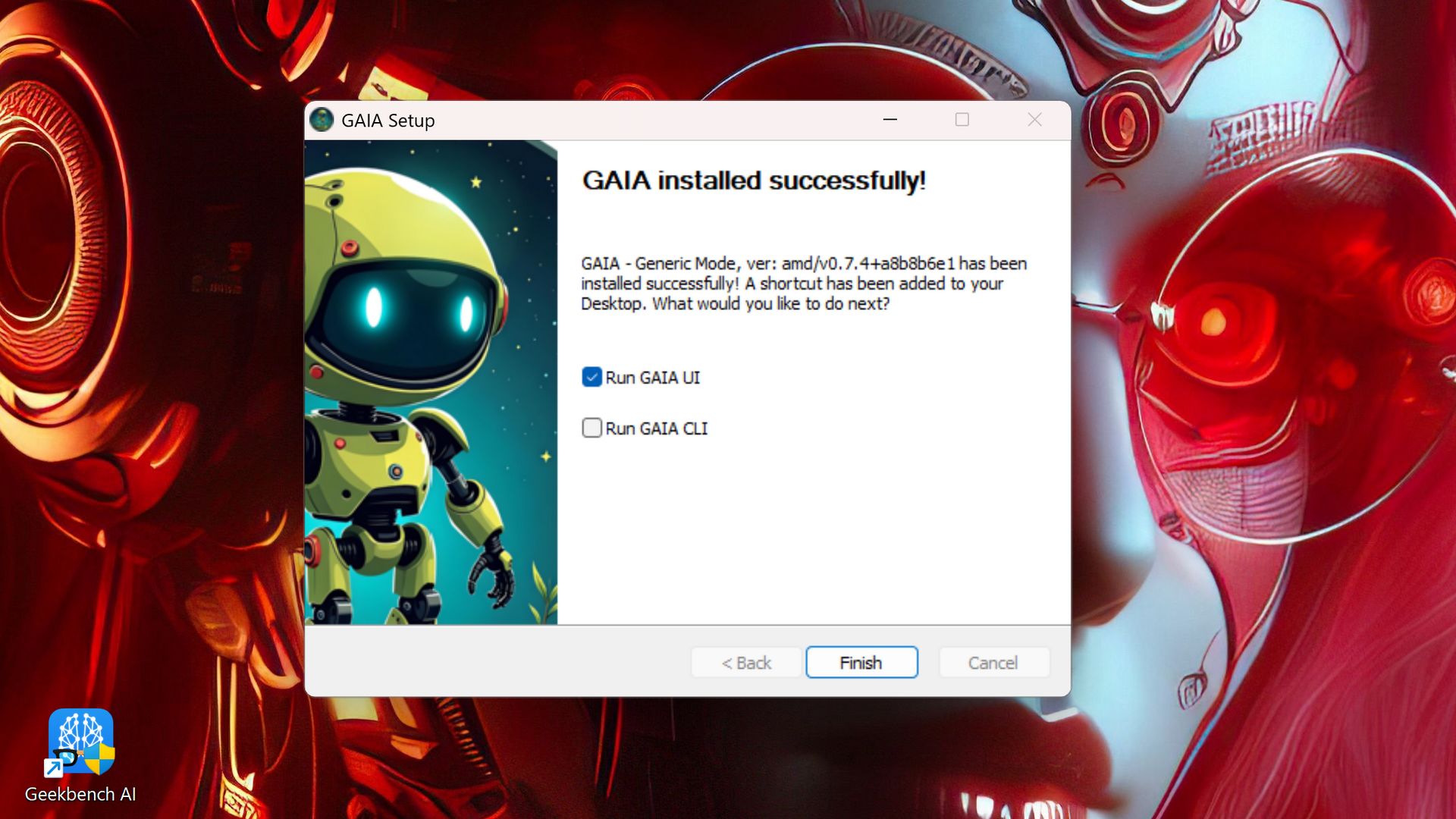
AMD GAIA w praktyce
Jedną z wyróżniających cech GAIA jest wykorzystanie agenta Retrieval-Augmented Generation (RAG). Ten potok łączy model językowy (LLM) z bazą wiedzy, umożliwiając agentowi wyszukiwanie istotnych informacji, rozumowanie, planowanie oraz korzystanie z narzędzi zewnętrznych w czacie. Efektem mają być bardziej precyzyjne i kontekstowo świadome odpowiedzi.
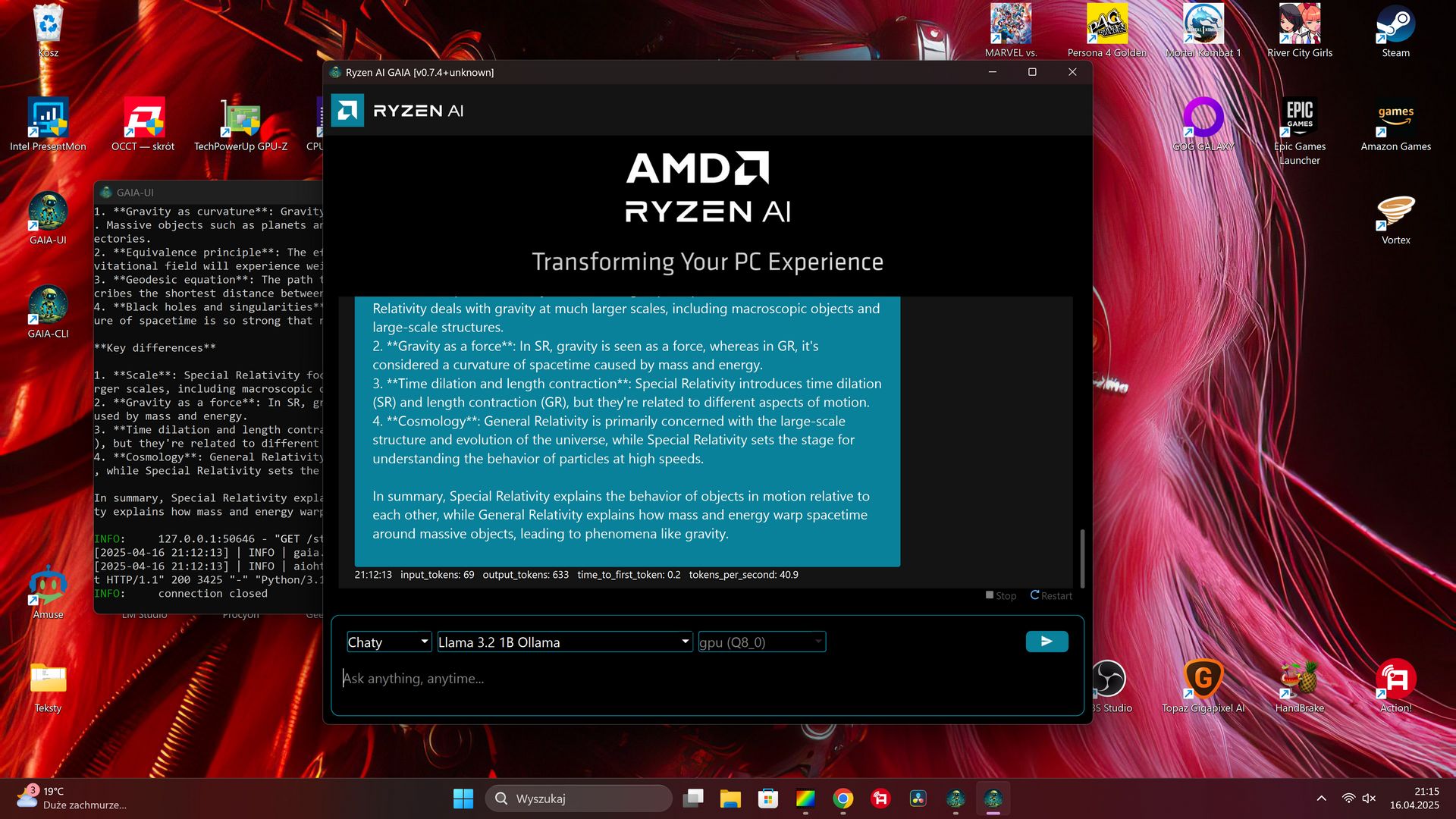
Obecnie AMD Gaia daje dostęp do następujących opcji:
-
Chaty: Chatbot oparty na LLM z archiwum rozmów.
-
Clip: Agent RAG przeznaczony do wyszukiwania na YouTube.
-
Joker: Prosty generator żartów.
-
Simple Prompt Completion: Brak agenta (do celów testowych i ewaluacyjnych).
Kolejni agenci są obecnie w fazie rozwoju, a deweloperzy są zachęcani do tworzenia oraz wnoszenia własnych rozwiązań. Wkrótce przekonamy się z jakim skutkiem.
Instalacja i uruchomienie wersji Generic na APU Phoenix przebiega bez żadnych problemów. Automatycznie zostaną zainstalowane takie pakiety jak Python, miniconda, FFmpeg, czy Ollama (tylko w wersji Generic). W przypadku Chaty w wersji Generic dostępne są następujące modele (oczywiście zmiana modelu wiąże się również z jego pobraniem, co dzieje się automatycznie):
-
Llama 3.2 1B Ollama
-
Llama 3.2 3B Ollama
-
Llama 3.1 8B Ollama
-
DeepSeek R1 1.5B Ollama
-
DeepSeek R1 7B Ollama
-
DeepSeek R1 8B Ollama
-
DeepSeek R1 14B Ollama
-
DeepSeek R1 32B Ollama
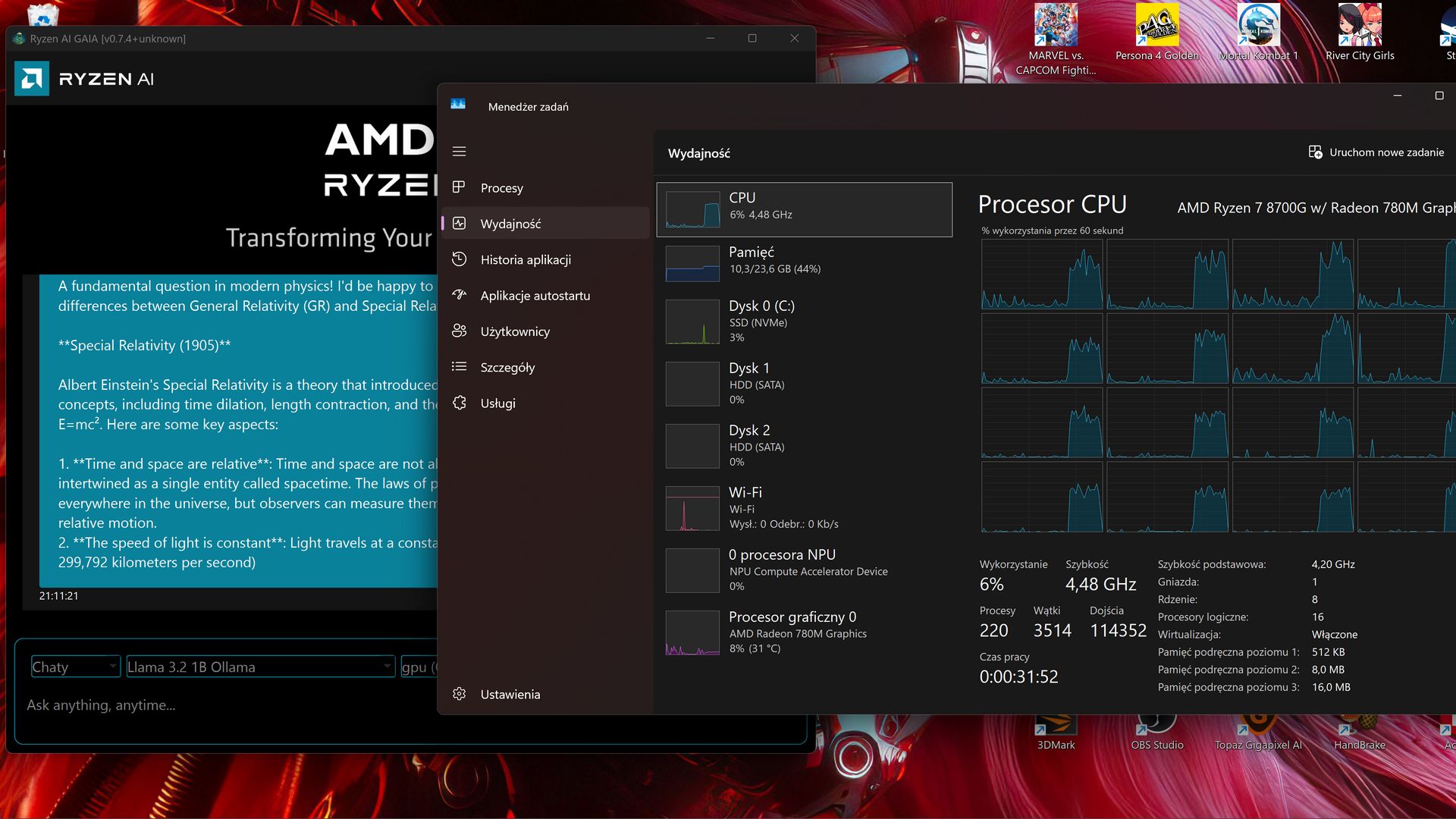
Jak widać na powyższym zrzucie ekranowym wersja Generic działa na CPU i powinna zadziałać na praktycznie dowolnym sprzęcie.
Oczywiście informacja o tym, że wersja Hybrid (iGPU + NPU) wspiera Ryzen AI 300 nie powstrzymała mnie od prób zainstalowania na AMD Phoenix. Sam proces instalacji kończy się sukcesem, ale przy próbie uruchomienia modelu pojawia się błąd dotyczący instalacji pakietu Lemonade od Hugging Face i pomimo moich usilnych prób nie udało mi się go wyeliminować. Problemy mogą robić również zbyt stare, jak i.. zbyt nowe sterowniki NPU. Szczegóły znajdziecie w opisie instalacji na GitHubie. Co ciekawe, w dziale Download oprócz wersji Generic i Hybrid znajduje się również informacja o wersji NPU, ale jak na razie nie jest ona dostępna do pobrania.
Wersja Hybrid pozwala na wybór następujących modeli:
-
Llama 3.2 1B Instruct
-
Llama 3.2 3B Instruct
-
Phi 3.5 Mini Instruct
-
Phi 3 Mini Instruct
-
Llama 2 7B Chat
-
Qwen 1.5 7B Chat
-
Mistral 7B Instruct
AMD GAIA - a komu to potrzebne?
AMD Gaia to krok w dobrym kierunku, ale jak na razie to raczej proteza, niż pełnoprawne oprogramowanie. Na przykład proces odinstalowania polega na usunięciu plików z folderu AppData, modeli z folderu cache oraz ikon z pulpitu. Wygląda to na razie jak zestaw pakietów połączonych skryptami.
Fajnie, że posiadacze Ryzen AI 300 mogą wykorzystać mechanizm Hybrid (czyli obliczenia równocześnie na NPU i iGPU), ale cała reszta może tylko uruchamiać obliczenia na CPU i czekać na kolejne wersje programu, które być może obsłużą starsze modele NPU (oraz iGPU).
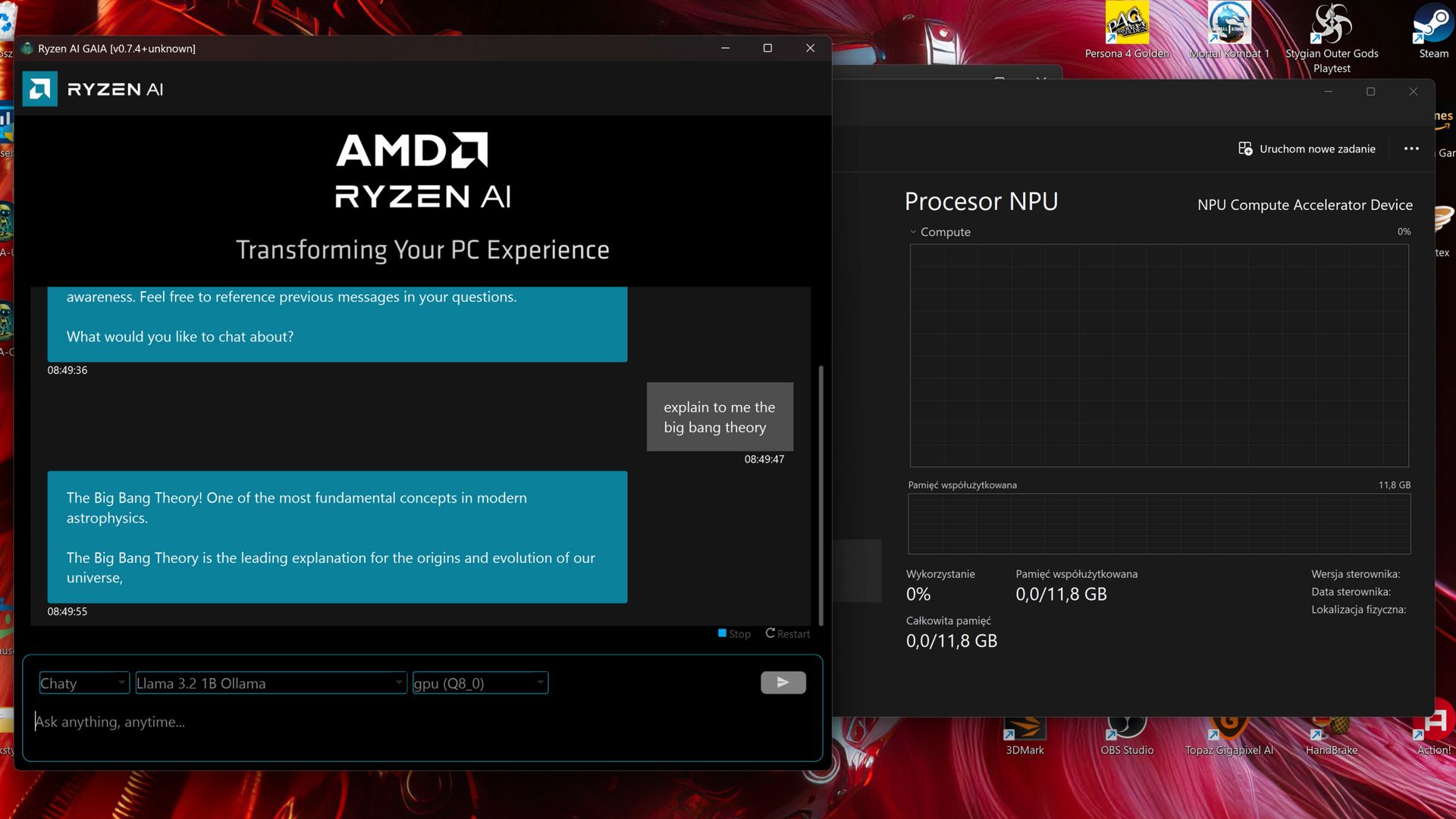
Oprogramowanie wykorzystujące NPU w procesorach - zwłaszcza w starszych wersjach - wciąż jest w powijakach. Po raz kolejny okazało się, że software nie nadąża za rozwojem sprzętu. W takim tempie, zanim powstanie oprogramowanie które z skorzysta z mojego NPU, to ten układ nie będzie się już do niczego nadawać. A już teraz w stosunku do generacji XDNA 2 jest mocno przestarzały.
Posiadając NPU w desktopie (Phoenix, czyli XDNA 1) ani razu nie miałem okazji sensownie wykorzystać tego układu, a przypomnijmy, że jego premiera miała miejsce prawie 1,5 roku temu. Jeszcze jakiś czas temu trzeba było kombinować, żeby w Windows w ogóle pojawił się wskaźnik pomiaru obciążenia NPU.
Takie aplikacje do generowania obrazów AI jak (wspierane przez AMD) Amuse AI chwalą się obsługą Strix Halo i Krackan, natomiast przy próbie wykorzystania NPU w desktopowym Phoenixie bezczelnie się wywalają (nawet w wersji 3.0). Jakieś wsparcie w obliczeniach przy renderowaniu filmów też by się przydało. DaVinci Resolve, czy nawet windowsowe aplikacje jak Paint coś tam już ponoć potrafią, ale ponownie - nie na moim NPU (większość opcji zapewne dostępna jest dla Snapdragonów). Cóż, czekam dalej.
Spodobało Ci się? Podziel się ze znajomymi!









Pokaż / Dodaj komentarze do:
Czerwoni też mają platformę do lokalnej AI. Sprawdzam jak działa AMD GAIA